
El clustering con Windows Server
Introducción a la clustering
1. Aspectos generales
El clustering consiste en reunir varias máquinas en una sola entidad lógica con un posible doble objetivos: evitar fallos de hardware, aumentar los recursos disponibles o ambas cosas a la vez.
En este libro ya hemos hablado del clúster DHCP, que permite tener un servidor en standby por si el primero falla o distribuir la carga de trabajo entre los dos servidores.
En este capítulo, veremos la agrupación en clústeres de servidores, con varios servidores que ejecutan un servicio como Hyper-V o SQL o un servidor de archivos, combinados en una única entidad.
En un clúster, cada servidor se denomina nodo y Windows Server puede gestionar clústeres de 2 a 64 nodos. Estos nodos pueden ser máquinas físicas o virtuales. Los clústeres se pueden configurar en un dominio de Active Directory, en varios dominios diferentes o incluso en un Workgroup sin dominio.
Normalmente, los servidores de un clúster, los nodos, compartirán un almacenamiento común a través de la red. Este almacenamiento puede adoptar varias formas, como armarios JBOD, almacenamiento iSCSI, simples recursos compartidos en un pool de almacenamiento, etc. Lo importante es que todos los nodos puedan acceder a los datos de la misma forma. También es posible agrupar el almacenamiento local de cada servidor del clúster. Es lo que se conoce como infraestructura...
Instalación del trabajo práctico

En este trabajo práctico, dispondremos de cuatro servidores, incluyendo un controlador de dominio, dos servidores en los que podemos instalar diferentes roles y un servidor de almacenamiento. Todos los servidores son miembros del dominio, lo que facilitará la autenticación y la resolución DNS. Todos los servidores tienen una interfaz gráfica.
Los servidores del clúster y el servidor de almacenamiento tienen dos tarjetas de red. La primera se encuentra en una red puente (bridge) o externa para su hipervisor, que servirá como red de gestión y comunicación del clúster y que, por tanto, tendrá acceso a la red real. El direccionamiento IP de las tarjetas de red de la red de gestión se debe adaptar al direccionamiento IP de su red real.
La otra tarjeta de red se encuentra en una red sólo de host en su hipervisor, sin acceso a la red real y será utilizada por el clúster para acceder a este almacenamiento. El controlador de dominio no tiene acceso a esta red.
El trabajo práctico evolucionará a lo largo de este capítulo, pero esta es una base sólida para descubrir la agrupación en clústeres en Windows Server. No dude en tomar instantáneas de su infraestructura con regularidad.
Clúster de conmutación por error
1. Configuración del almacenamiento
Lo primero que hay que implementar en un clúster de conmutación por error es el almacenamiento. Vamos a crear almacenamiento iSCSI en el servidor WIN-STOCK del trabajo práctico. También necesitamos crear un testigo para el quórum del clúster.
Ya hemos visto cómo configurar iSCSI en el capítulo Almacenamiento de este libro, pero vamos a revisar este proceso añadiendo algunos conceptos y comandos PowerShell más.
a. Preconfiguración de iniciadores iSCSI
Comenzaremos habilitando los iniciadores iSCSI en los dos servidores del clúster, lo que almacenará en caché sus IQN para que no tengamos que rellenarlos manualmente al crear el destino en el servidor de almacenamiento.
Para habilitar los iniciadores, inicie y configure el servicio iSCSI en ambos equipos. Para ello, utilice PowerShell desde el controlador de dominio:

Comprobación de iniciadores con PowerShell:
Invoke-Command serv1,serv2 { Get-InitiatorPort } El resultado muestra que se han creado los IQN de los iniciadores:
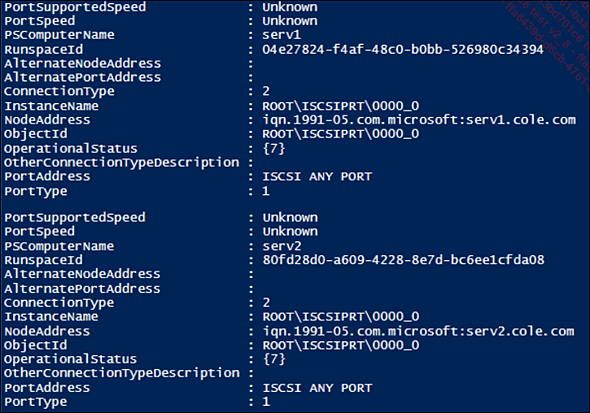
En el siguiente comando, especifique el servidor de almacenamiento a los iniciadores, lo que les permitirá hablar con él. Esto almacenará en caché los IQN de los iniciadores en el servidor de destino, por lo que no tendrá que rellenarlos manualmente. La IP es la del servidor WIN-STOCK en la red de almacenamiento.
Invoke-Command serv1,serv2 { New-IscsiTargetPortal
-TargetPortalAddress 10.10.10.100 } b. Configuración del servidor de almacenamiento
Añade un disco de 200 GB al servidor de almacenamiento y formatéalo en ReFS.
Añada el servicio de rol iSCSI Targer Server en el servidor.
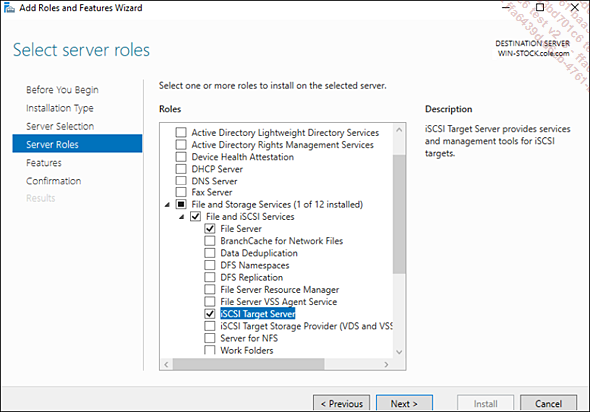
Inicie la creación del disco virtual iSCSI en el nuevo volumen.

Dale un nombre, establece su tamaño en 150 GB, con asignación dinámica y haz clic en Next.
Cree el destino iSCSI y asígnele un nombre.
En la página siguiente, haga clic en Add para configurar el acceso de los iniciadores. Los iniciadores ya se han añadido a la caché.
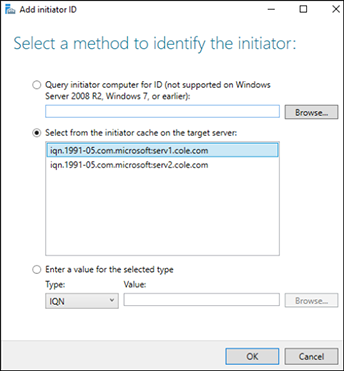
Añada los dos IQN para los dos servidores.

Ignore los demás ajustes y haga clic en Next hasta llegar a la ventana de resumen y, a continuación, confirme....
Servidor de archivos SOFS
1. Introducción al SOFS
Un servidor de archivos SOFS (Scale Out File Server), también conocido como "servidor de archivos con escalabilidad paralela", es un servidor en el que todos los nodos del clúster están activos al mismo tiempo.
De hecho, en el clúster de servidores de archivos que construimos en la sección anterior de este capítulo, sólo un nodo estaba activo y el otro estaba en espera, en caso de fallo y conmutación por error. Sólo el nodo activo estaba conectado a los recursos compartidos.
En un servidor SOFS, todos los nodos están conectados a los recursos compartidos al mismo tiempo y todos participan en el encaminamiento de datos a los clientes, lo que permite un ancho de banda mucho mayor. Este mecanismo utiliza una característica de SMB 3, que es SMB multicanal.
Otra ventaja de los servidores SOFS es que podemos añadir fácilmente servidores al clúster, lo que aumenta aún más el ancho de banda y garantiza una mayor tolerancia a fallos.
También será posible desconectar un nodo para mantenimiento sin tener que preocuparse por la conmutación por error.
Para poder conectar varios nodos a un recurso compartido, el sistema utiliza CSVs (Cluster Shared Volumes). Estos volúmenes no utilizan NTFS o ReFS, que no permiten montar un volumen en varios sitios, sino un sistema de archivos especializado, CSVFS. Esto se consigue añadiendo una capa de software entre los volúmenes NTFS o ReFS y el clúster.
Esta capa de software separa los metadatos de los datos de usuario, de modo que los metadatos se pueden gestionar con varios nodos. NTFS y ReFS permiten acceder...
Clúster Hyper-V
Ahora es el momento de crear un clúster de servidores Hyper-V. Para ello, necesitamos que las dos máquinas SERV1 y SERV2 tengan instalado el rol Hyper-V. Esto sólo es posible si la virtualización anidada está habilitada en las máquinas virtuales de su hipervisor.
Tenga en cuenta que al instalar Hyper-V se instalará un nuevo adaptador de tarjeta de red en cada uno de los servidores. Recuerde comprobar su configuración antes de continuar.
1. Instalación del clúster Hyper-V
a. Preparación del clúster
Una vez activada la virtualización anidada en los procesadores de las máquinas, instale Hyper-V en SERV1 y SERV2.
Elimine el rol de clúster SOFS y vuelva a realizar un CSV desde el almacenamiento existente.
Después de eliminar el rol SOFS del clúster, vaya al disco y añádelo a los CSVs del clúster.

Desde el explorador de uno de los servidores, vaya al CSV y cree una carpeta para colocar las máquinas virtuales.

b. Crear una primera máquina virtual
En el administrador del clúster, haga clic con el botón derecho del ratón en Roles, seleccione Virtual Machines y después New Virtual Machine.
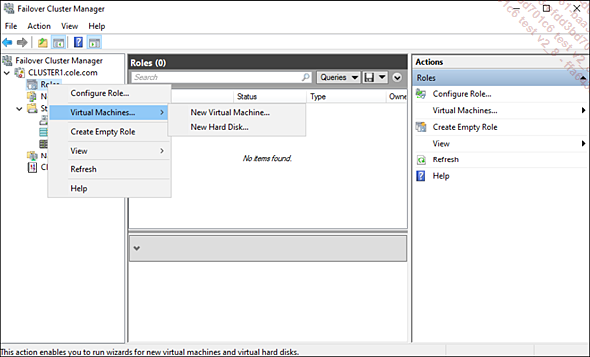
A continuación, deberá decidir qué servidor alojará la máquina virtual.

Se inicia el asistente para la creación de una máquina virtual. Dé un nombre a la máquina y colóquela en la carpeta creada en el volumen CSV.

Cree una máquina de generación 2 con 1024 MB de memoria y asignación dinámica y conéctela al conmutador externo, creado cuando se instaló Hyper-V.
A continuación, en la configuración del disco VHDX, compruebe que el sistema ha colocado el disco en el volumen compartido.

Diga que desea instalar el sistema operativo más tarde y confirme hasta que se cree la máquina virtual.
Verá un mensaje de resumen...
Espacio de almacenamiento directo
1. Introducción
a. Conceptos básicos
Los espacios de almacenamiento directo, también conocidos como "storage space direct" o "S2D" por Microsoft, son una tecnología que permite agregar el almacenamiento local de los servidores que componen un clúster en un pool de almacenamiento. Esto permite crear lo que se conoce como, una infraestructura hiperconvergente.
Esto permite combinar tipos de disco SSD y HD, en SATA, NVME o SAS, para disponer de una caché de escritura, almacenamiento de terceros y resiliencia de tipo mirroring o paridad de pools de almacenamiento. Se pueden utilizar volúmenes NTFS o ReFS.
También existe un tipo de despliegue para espacios de almacenamiento directo conocido como "convergente", en el que hay dos clústeres: un clúster SOFS para el almacenamiento otro para los recursos informáticos. En este libro, sólo hablaremos de arquitecturas hiperconvergentes.
Los almacenes directos utilizan simultáneamente varias tecnologías de Windows Server, como los clústeres de conmutación por error, los volúmenes compartidos CSV y los pools de almacenamiento y añaden una función denominada bus de almacenamiento virtual.
El bus de almacenamiento virtual permite a los servidores del clúster, ver los discos conectados a los demás servidores. La comunicación entre los servidores y los distintos discos, se realiza simplemente a través de las conexiones Ethernet de los servidores.
Las áreas de almacenamiento directo requieren Windows Server 2022 Datacenter Edition y se pueden combinar hasta 16 servidores en un área de almacenamiento directo hiperconvergente.
b. Conceptos básicos de hiperconvergencia
El concepto esencial de la hiperconvergencia es que el almacenamiento y la potencia de cálculo están en la misma máquina. Esto tiene una serie de ventajas. Las infraestructuras hiperconvergentes (HCI) ofrecen las siguientes ventajas en comparación con las infraestructuras de almacenamiento SAN tradicionales.
-
Menores costes: una infraestructura hiperconvergente requiere menos servidores, menos dispositivos de red y ninguna bahía de almacenamiento externo. Esto supone un ahorro sustancial.
-
Menor complejidad: gestionar el sistema, la red y las bahías de almacenamiento utilizadas...
Balanceo de la carga de la red
1. Introducción
El balanceo de carga de red se lleva a cabo en Windows Server utilizando un tipo de clúster diferente de los clústeres de conmutación por error. En estos clústeres de balanceo de red, los servidores se denominan hosts.
El balanceo de carga de red es una característica de Windows Server, no un rol. Es una característica bastante antigua que ha evolucionado poco. Microsoft a menudo se refiere a ella por el acrónimo NLB (Network Load Balancer). Se puede gestionar utilizando una consola o PowerShell.
Si un host se cae, el balanceo de carga tiene lugar entre los hosts restantes y, cuando vuelve a estar disponible, se reincorpora al clúster de equilibrio de carga, se carga automáticamente y asume su parte del tráfico. La redistribución y el reequilibrio tardan un máximo de 10 segundos.
Se puede añadir un máximo de 32 hosts al clúster y los hosts se pueden añadir o eliminar de forma transparente. Los hosts deben tener configuraciones IP estáticas; el balanceo de red desactiva el protocolo DHCP en las tarjetas de red para las que está configurado.
Microsoft recomienda tener al menos dos tarjetas de red por host, una para la red de gestión y otra para el acceso de clientes. Es en las tarjetas de acceso a la red cliente, donde debe tener lugar el balanceo de carga. Es más, algunos modos de balanceo de carga requieren dos tarjetas de red.
La forma en que el clúster equilibra la carga se definirá mediante reglas denominadas "filtros" en la terminología de Microsoft.
Existe otro tipo de balanceo de carga de red en Windows Server, el Software Load Balancer. Está especializado en el equilibrio en redes virtuales y en la gestión del tráfico de las máquinas virtuales.
2. Preparación del trabajo práctico
Para implementar el balanceo de carga, vamos a utilizar dos servidores con el servidor web IIS instalado y un controlador de dominio. El rol de servidor web sólo se utilizará para comprobar que el balanceo de carga funciona.
Los dos servidores IIS tendrán dos tarjetas de red:
-
HOTE1 192.168.108.101/24 y 10.10.10.101/24
-
HOTE2 192.168.108.102/24 y 10.10.10.102/24
El controlador de dominio para el dominio cole.com será 192.168.108.200/24. Todas las máquinas están...
Clúster extendidos
Los clústeres extendidos, también conocidos como stretch clusters, son clústeres de conmutación por error que abarcan varios sitios geográficos remotos y pueden conmutar por error de un sitio geográfico a otro. Es difícil demostrar aquí la creación de clústeres extendidos, dados los recursos físicos necesarios, pero repasaremos los conceptos principales.
1. Presentación y conceptos básicos
En un clúster extendido, la conmutación por error de los nodos tendrá lugar dentro del mismo sitio, y si todos los nodos de un sitio se caen, las cargas de trabajo pasarán a los nodos del otro sitio. En un clúster extendido, los nodos de ambos sitios pueden estar activos al mismo tiempo.
Es posible crear clústeres extendidos con un mínimo de dos servidores, uno por sitio. En este caso, la conmutación por error en el mismo sitio no será posible. Podemos poner un máximo de 64 servidores en un clúster extendido.
Esto implica la replicación de almacenamiento de un sitio a otro, que es proporcionada por la funcionalidad de réplica de almacenamiento que vimos en el capítulo El almacenamiento de este libro.
La réplica de almacenamiento en un clúster extendido soporta sincronización síncrona y asíncrona. Este es el único caso en el que la conmutación...