
Feature Engineering
Feature Engineering, conceptos básicos
Feature Engineering se podría traducir con algo de imaginación como ingeniería de datos y, con menos de 100 000 entradas en Google, podría parecer el pariente pobre del machine learning, con sus 20 millones de enlaces. Sin embargo, esto a menudo representa más de la mitad del esfuerzo necesario en un proyecto de data sciences.
1. Posicionamiento del problema
La Feature Engineering se refiere a las técnicas de ingeniería utilizadas para trabajar con los atributos del problema que se está estudiando, y representa uno de los aspectos más delicados de la data sciences.
De hecho, las features de un problema dado no siempre se muestran de forma natural y evidente.
Es normal que se necesite mucho esfuerzo para imaginar cuáles podrían ser los atributos correctos, crearlos, seleccionarlos, probarlos y transformarlos para hacerlos relevantes y digeribles por nuestros algoritmos. Las buenas predicciones requieren buenos atributos (en inglés predictors o features).
El trabajo de selección y configuración de los modelos, la medición de los errores de predicción (o de clasificación) y la cuidadosa interpretación de los resultados son tres elementos inseparables de la disciplina denominada Feature Engineering.
La idea general es refinar y transformar los datos sin procesar (data) para que nos proporcionen información enriquecida. Matemáticamente, esta ganancia o riqueza de la información se corresponde con una disminución de la entropía. De alguna manera, conseguir información significativa y utilizable reduce el desorden ambiental a través de nuestra comprensión del fenómeno estudiado.
A menudo, el primer escollo es determinar el objetivo mismo del estudio. De hecho, la pregunta no siempre es del todo explícita y es habitual traducir el objetivo del estudio en términos simplistas, pero lo suficientemente sencillos como para poder ser el objeto de una predicción (por ejemplo, sería difícil pretender predecir la satisfacción de los clientes sin tener una pista de cómo medirla).
2. A qué hay que prestar atención
La eficacia de los algoritmos depende en gran medida de la naturaleza y la calidad de los datos que se utilizan y, por lo tanto, aquí la negligencia...
PCA clásico, elementos matemáticos
La asimilación de este apartado no es imprescindible para la implementación operativa de los conceptos descritos anteriormente.
Esta pequeña sección le debería permitir leer y descifrar la literatura sobre la PCA de manera provechosa y proporcionar una descripción general de algunas técnicas matriciales comunes (incluido el cambio básico).
Con las siguientes convenciones:
-
n: número de filas de datos.
-
p: número de features (es decir, dimensiones).
-
q: número (reducido) de dimensiones, que nos gustaría que fuera menor que p.
-
i: índice, de 1 a n.
-
j: índice, de 1 a p.
-
k: índice, de 1 a q.
-
X: matriz (xij) de datos centrados, o centrados y reducidos (hemos aplicado una transformación previa: centrado significa que hemos restado de cada columna su media, reducido significa que también hemos dividido este resultado por la desviación típica de la columna; en la literatura inglesa centrado y reducido es z-score). Atención: dos columnas no deben ser colineales (es decir, una columna no debe ser completamente proporcional a la otra).
-
X’: matriz (x’ij) de los datos transformados en una nueva base.
-
X’’: matriz (x’’ik) de datos que se representan en una base truncada de q dimensiones, ese es el objetivo.
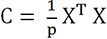 , que es la matriz de covarianza -si
X solo estuviera...
, que es la matriz de covarianza -si
X solo estuviera...Reducción de los datos (data reduction)
Esta pequeña sección no se relaciona estrictamente con la «Feature Engineering», sino que también se relaciona con la limpieza de datos antes del uso de un algoritmo, a menudo vinculado al machine learning. Debido a que la confusión es común, echemos un vistazo a esta noción. Aquí el problema es el contrario, la preparación ya no se refiere a las «columnas» sino a las «filas».
Esta operación consiste en la extracción y posterior uso de un subconjunto coherente de filas resultantes de un conjunto de datos de gran volumen. Algunas veces, es útil para ahorrar recursos de la máquina, pero también para mejorar la eficiencia de ciertos algoritmos o para reducir su exposición al «ruido».
Esta noción de ruido es bastante intuitiva en el caso de la interpretación de imágenes o sonidos, donde estamos acostumbrados a la idea de que los sensores son menos eficientes de lo deseado e introducen «ruido» en ellos. Este problema de introducción de ruido no es específico de los sensores «físicos»: el «ruido» se puede introducir accidentalmente en cualquier tipo de datos, dependiendo del proceso de captura de la información.
Una de las técnicas comunes para reducir datos es seleccionar ciertos «puntos»...
Reducción de la dimensionalidad y entropía
Puede parecer molesto basar toda su estrategia de reducción de dimensionalidad en álgebra lineal, como se hace con la PCA, porque estas técnicas podrían incorporar ciertas suposiciones simplificadoras de la naturaleza de los datos sobre los que el data scientist tiene poco control.
El concepto de «entropía e información compartida» descrito en la introducción de este libro parece más general y, por lo tanto, parece legítimo construir parte de su estrategia sobre estos conceptos.
En el capítulo Introducción, hemos expresado la información compartida por dos variables representada por la siguiente expresión (en función de la entropía): I(X,Y) = H(X) + H(Y) - H(X,Y).
Esta expresión desaparece en el caso de dos variables dependientes. Aquí, la noción de dependencia no supone una dependencia lineal, ni siquiera una dependencia lineal después de cualquier transformación.
1. Descripción teórica del problema
Llamaremos S (por set) al conjunto formado por nuestras variables explicativas xi, e y a nuestra variable de respuesta.
Nuestro objetivo es seleccionar un subconjunto de S que incluya p features, es decir, ciertas variables explicativas (features). Este subconjunto se denomina s y m es su número de features.
Por tanto, necesitamos un criterio de selección.
Como primera aproximación, imaginamos rápidamente que debemos encontrar el conjunto de features s que tiene la mayor dependencia del objetivo y. De hecho, si un conjunto de features tiene más información compartida con el objetivo que otro, este conjunto será el más capaz de predecir el objetivo.
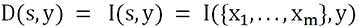 .
.Entonces, la idea será explorar todas las posibilidades de los conjuntos incluidos en S, calcular esta dependencia y quedarnos con la más alta.
Cuando p es pequeño, esto provoca el cálculo de un gran número de combinaciones de información mutua entre cada posible subconjunto s e y.
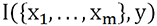 , aquí en el caso continuo, es un poco
tosco:
, aquí en el caso continuo, es un poco
tosco: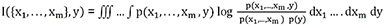
En realidad, hacer esto una gran cantidad de veces...


