
Modelizar y evaluar
Fase de modeling
La fase de Modeling es la continuación de la fase de Data Preparation. Consiste en crear uno o varios modelos para llevar a cabo la tarea determinada en Business Understanding.
Estos modelos deberán mejorarse, perfeccionarse, evaluarse y compararse, de modo que durante la fase de evaluación solo se propongan los que mejor se adapten al contexto empresarial.
Esta modelización puede dar lugar a modificaciones de los datos, ya sea en términos de formato, unidad o tipo. Estas modificaciones obligan a volver a la fase de preparar los datos, y estas iteraciones pueden tener lugar varias veces al día.
De hecho, algunos algoritmos imponen fuertes restricciones a los datos aceptados como entrada. Además, añadir o modificar datos a veces puede mejorar los resultados. Es el caso, por ejemplo, de la normalización.
En la práctica, es a partir de la fase de modelado cuando más se utilizará la biblioteca Scikit-learn. Toma el relevo de Pandas, que se utilizaba para cargar, analizar y preparar los datos.
Scikit-learn es una biblioteca muy completa, con muchos algoritmos y también muchas métricas o funciones para preparar datos. Además, cada método tiene muchos parámetros.
La presentación de este libro no es en absoluto exhaustiva. La documentación completa sobre la librería puede consultarse en: https://scikit-learn.org/stable/
Crear un conjunto de validación
En la fase de Data Preparation se crearon dos subconjuntos:
-
El dataset train (de entrenamiento) utilizado para crear los modelos.
-
El dataset test (de prueba) sirve para validar su adaptación al caso real y evaluarlos.
Para la gran mayoría de algoritmos, es necesario determinar una serie de hiperparámetros. Éstos sirven para dirigir y controlar el proceso de aprendizaje. En función de los valores elegidos, adaptados o no, los resultados pueden variar de un modelo muy eficiente a un modelo completamente inutilizable.
El dataset test no puede utilizarse para evaluar qué parámetros son los mejores, ya que de lo contrario habría un fuerte sesgo en la evaluación.
Por lo tanto, se necesita un tercer dataset: el conjunto de validación. Así, el conjunto train se separará en un conjunto que se utilizará realmente para el entrenamiento y otro que se utilizará para determinar los parámetros.
Normalmente, se utilizará un 10% de los datos originales para la validación. Sin embargo, al igual que en la creación del conjunto test, cuantos más datos haya disponibles, menor será el porcentaje para el conjunto de validación.
Una variante de la creación de un conjunto de validación se denomina «validación cruzada» (cross validation). Consiste en crear varias separaciones de Aprendizaje...
Preparar el dataset
Los datasets Iris, Titanic y Boston se utilizarán en los siguientes capítulos. Así que se deben cargar y ajustar en el formato correcto para poder modelarlos.
Los preparativos vistos en el capítulo anterior se simplificarán al mínimo para crear los modelos. En consecuencia, no se optimizarán los resultados.
Scikit-learn solo acepta parámetros numéricos para los diferentes algoritmos de Machine Learning. Por lo tanto, todas las variables categoriales deben cuantificarse.
Los datos no se normalizarán previamente. De hecho, algunos algoritmos no lo necesitan y se conservarán los datos brutos. Sin embargo, no debería haber más datos faltantes, que deberían eliminarse o imputarse.
1. Dataset Iris
Este dataset es bastante sencillo, ya que solo contiene variables numéricas y ningún dato faltante. Como no tiene un conjunto de prueba, tenemos que crear uno.
Su preparación completa es, por tanto, la siguiente:
import pandas as pd
from sklearn.model_selection import train_test_split
# Carga
iris_df = pd.read_csv("iris.csv")
# Separar entrenamiento - prueba
y = iris_df['class']
X = iris_df.drop(labels='class', axis=1)
train_X_iris, test_X_iris, train_y_iris, test_y_iris =
train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=42) 2. Dataset Titanic
La preparación del dataset Titanic es más compleja. Contiene un conjunto test, pero este no tiene la variable objetivo...
Crear modelos
1. Proceso iterativo
Una vez listos los datos, hay que crear los modelos. En la práctica, se trata de un proceso altamente iterativo con el siguiente ciclo:
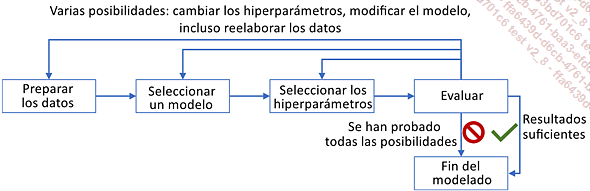
Dentro de una iteración CRISP-DM, esta fase normalmente se detendrá por falta de tiempo. Sin embargo, tendrá un impacto importante en la continuación o no de otras iteraciones:
-
Si los resultados son suficientemente buenos, la fase siguiente a la evaluación será la implementación (puesta en marcha).
-
Si a pesar de todas las pruebas, los resultados siguen siendo insuficientes y el proyecto se interrumpe, de acuerdo con el cliente. Esto puede ocurrir si los datos suministrados no son de suficiente calidad o cantidad, o si son irrelevantes para la tarea en cuestión. Otra causa para detener el proyecto puede ser la falta de un algoritmo de alto rendimiento para esta tarea en el estado de la tecnología punta. En algunos casos, pararlo puede ser simplemente una pausa, ya que pueden desarrollarse nuevos algoritmos o recopilarse nuevos datos.
En todos los demás casos, se realizará una iteración adicional, modificando:
-
Los hiperparámetros del modelo actual, especialmente si los resultados parecen prometedores.
-
El modelo elegido, si parece que no va a dar buenos resultados. En función de la evaluación, puede elegirse un modelo más o menos complejo.
-
Modificar o añadir pasos en la preparación de los datos, por ejemplo para transformar datos numéricos en variables categoriales o viceversa, o calculando nuevas variables a partir de las anteriores.
2. Crear un modelo en Scikit-learn
La creación de un modelo en Scikit-learn es muy sencilla y consta de tres pasos:
-
Crear el modelo, instanciando un algoritmo (llamado estimator) y especificando los hiperparámetros elegidos.
-
Aprendizaje, mediante el método fit, proporcionándole los datos de los parámetros
-
Inferencia mediante el método predict
Así...
Puesta a punto de los modelos (fine-tuning)
1. Optimizar los hiperparámetros
La optimización de hiperparámetros consiste en crear varias sesiones de entrenamiento utilizando el mismo algoritmo, pero con diferentes hiperparámetros.
En función de los valores elegidos, algunos modelos pueden estar muy bien adaptados y ser, por tanto, eficientes o, por el contrario, inutilizables. Además, en el caso de los algoritmos con varios hiperparámetros, estos suelen estar vinculados, y cambiar uno de ellos puede requerir cambiar todos los demás.
En teoría, tendríamos que probar todos los conjuntos posibles de hiperparámetros. En la práctica, esta búsqueda exhaustiva es imposible.
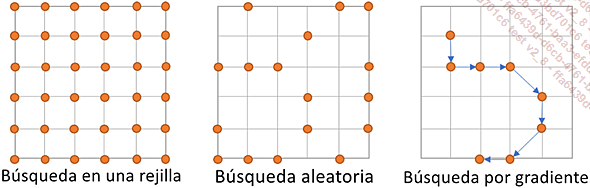
Las principales estrategias son:
-
búsqueda en una rejilla (grid search): para cada hiperparámetro, se proporciona un número determinado de valores, y la búsqueda probará todas las combinaciones posibles;
-
búsqueda aleatoria (random search): solo se probará un subconjunto de las combinaciones posibles. La búsqueda aleatoria puede tomar sus valores de listas suministradas o seleccionándolos de intervalos continuos;
-
búsqueda por gradiente (gradient-based optimization): en función de los resultados obtenidos en diferentes conjuntos, la búsqueda se guiará en la dirección del gradiente hacia la optimización de la métrica elegida.
2. Aplicar en Scikit-learn
Solo los dos primeros tipos de búsqueda existen en Scikit-learn. El método debe entonces ser suministrado con el estimator utilizado, los hiperparámetros con los valores o distribuciones, y la métrica (s) para ser optimizado.
En ambos casos, el primer paso consiste en definir una lista de parámetros que se va a optimizar...
Métodos de ensamble
En la actualidad, los mejores resultados en los retos rara vez se obtienen utilizando un único modelo. Los mejores resultados se obtienen utilizando varios modelos, que se combinan y/o compensan entre sí.
Con varios modelos diferentes, los errores de uno en particular pueden ser compensados por los demás modelos. Además, el resultado suele estar menos sujeto a sobreajuste, ya que la media de varios modelos suavizará las predicciones.
Existen tres enfoques para combinar varios modelos:
-
Bagging
-
Boosting
-
Stacking
1. Bagging
El término bagging procede de los términos «Boostrap Aggregating» (agregación de ensambles). Consiste en agregar modelos, cada uno de los cuales se ha creado sobre un subconjunto de los datos.
A partir del dataset de entrenamiento, se crearán aleatoriamente varios subconjuntos de datos. Se trata de un sorteo aleatorio restaurando el dataset después de cada tirada, por lo que los mismos datos pueden encontrarse en varios subconjuntos. Por el contrario, no es necesario que todos los datos hayan sido seleccionados al menos una vez.
En estadística, el bootstrap es una técnica que consiste en tomar aleatoriamente subconjuntos de datos, con restauración.
Se creará un modelo simplificado para cada subdataset. Tendrá menos parámetros que un modelo del mismo tipo creado para todo el dataset. Por ejemplo, para un árbol...




