
Algoritmos de aprendizaje no supervisado
Tareas de aprendizaje no supervisado
El aprendizaje no supervisado permite analizar un gran volumen de datos sin un conocimiento a priori de lo que se necesita.
Abarca cuatro tareas principales:
-
Clustering (Agrupar): el objetivo es agrupar los datos en conjuntos denominados clústeres, para estudiarlos o comprenderlos mejor.
-
Reducir las dimensiones: el objetivo es pasar de un dataset que contiene múltiples atributos a otro que solo contenga los más importantes para explicar el fenómeno estudiado.
-
Sistemas de recomendación: el objetivo es recomendar productos o servicios a los clientes basándose en datos históricos.
-
Asociaciones: el objetivo es vincular eventos para crear reglas del tipo «si A y B, entonces C en el x% de los casos».
Cada una de estas tareas se tratará por separado en este capítulo, siguiendo el mismo procedimiento: explicación de la propia tarea con ejemplos, las diferentes métricas de evaluación, los principales algoritmos y el código Scikit-learn correspondiente cuando la librería proporciona algoritmos.
La documentación completa de Scikit-learn para el aprendizaje no supervisado se encuentra en: https://scikit-learn.org/stable/unsupervised_learning.html
Clustering
1. Definición
Clustering (o agrupar) consiste en crear clústeres. Cada clúster es un dataset agrupados en función de sus similitudes.
A diferencia de una clasificación, las clases no se conocen de antemano. Corresponde al algoritmo determinarlas matemáticamente.
A continuación, es necesario realizar un análisis manual para asociar etiquetas a cada clase.
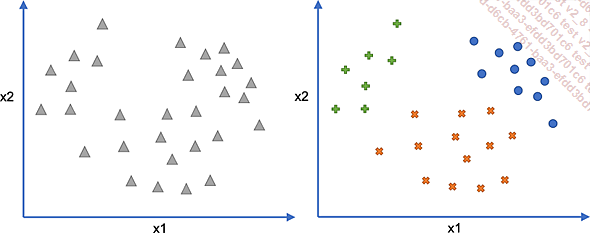
En el diagrama anterior, los datos originales (a la izquierda) están representados por los triángulos. La agrupación en tres clases (a la derecha) podría dar las siguientes categorías: cruces (x), redondas (o) y positivas (+).
Dentro de cada clase, hay coherencia: los puntos de la misma clase están próximos entre sí. Por el contrario, las clases son diferentes.
En este caso, un análisis de las clases permitiría definirlas como tales:
-
Clase cruzada (x): valor x2 bajo
-
Clase plus (+): valor x2 alto y valor x1 bajo
-
Clase redonda (o): valores x2 y x1 grandes
2. Ejemplos de casos prácticos
El uso principal es analizar las bases de datos de clientes, segmentándolas en «perfiles tipo». Cada perfil tipo podría entonces recibir ofertas dedicadas en función de sus centros de interés.
La agrupación también se utiliza en otras aplicaciones, como:
-
Segmentar productos para clasificarlos automáticamente en un sitio de venta en línea o para encontrar productos similares.
-
Clasificar usos, que permite diferenciar entre comportamientos típicos o usos potencialmente fraudulentos.
-
Seleccionar anuncios orientados, agrupándolos por similitud y ofreciendo anuncios pertenecientes a los mismos grupos que los ya vistos y/o en los que se ha hecho clic.
-
Detectar anomalías, creando clústeres de imágenes o casos similares y marcando como anómalo cualquier dato que se aleje de los clústeres existentes.
-
Crear sugerencias de contactos entre personas, por ejemplo, en redes sociales, basadas en similitudes entre las características de las personas (como sexo, profesión, edad, etc.).
El clustering también puede aplicarse antes del aprendizaje supervisado, con el fin de obtener una mejor comprensión de los datos, por ejemplo, durante la fase de Data Understanding.
Existen dos clases principales de algoritmos de agrupación: los basados en la distancia...
Reducir dimensiones
1. Definición
La tarea de reducir dimensiones es especial. Suele ser solo una etapa de un proceso más complejo.
Los datasets suelen tener un gran número de características (columnas). Estudiar datos con tanta información no es fácil, sobre todo porque las representaciones gráficas se limitan a 3 dimensiones.
Es más, para algunos algoritmos de Machine Learning, tener demasiadas dimensiones puede ralentizar el proceso de obtención de un buen modelo (o incluso imposibilitar el entrenamiento si no se dispone de suficiente memoria).
La tarea de reducción consiste, por tanto, en tomar un dataset que contenga múltiples columnas y extraer los ejes principales limitando el número de características que se van a estudiar.
2. Ejemplos de casos prácticos
Los dos casos prácticos principales están relacionados con la comprensión/visualización de datos, o con preparar los datos antes de usar otro algoritmo de Machine Learning.
En el caso de la comprensión y/o visualización de datos, he aquí los principales usos:
-
Visualizar datos complejos, por ejemplo, para tener una indicación de qué gráficos son los más significativos y que expliquen los datos al máximo posible.
-
Descubrir tendencias que no son visibles en los ejes iniciales, cambiando los puntos de referencia permitiendo aparecer límites de tipo lineales.
-
Estimar el ruido en los datos, calculando la parte explicada por unas cuantas características.
En el segundo caso, el de preparar los datos, he aquí algunos usos:
-
Limitar las dimensiones a las principales, para tener menos características que tener en cuenta posteriormente en el proceso, lo que también puede simplificar la preparación (solo se preparan las columnas útiles).
-
Eliminar la redundancia en las características. La mayoría de los algoritmos dan resultados muy pobres si hay redundancias, colinealidades o correlaciones entre los distintos campos.
-
Reducir la huella de memoria y, por tanto, el tiempo de cálculo de determinados algoritmos, limitando la cantidad de datos presentes en los datasets sin perder ejemplos.
-
Evitar o limitar el sobreajuste, eliminando el ruido previo.
Reducir las dimensiones de los datos disponibles tiene, pues, muchos usos posibles, sea cual sea el campo o el tipo...
Sistema de recomendación
1. Definición
Un Sistema de Recomendación (Recommender System) es un algoritmo que aconseja contenidos basándose en datos históricos
Los sistemas de recomendación están presentes en todas las plataformas de ocio:
-
Música (Deezer, Spotify...)
-
Vídeos (YouTube...)
-
Películas y series (Disney +, Netflix, Amazon Prime Videos...)
-
Productos (Amazon, Cdiscount...)
-
Contactos o feeds (LinkedIn, Facebook, Instagram, etc.)
-
Formación (LinkedIn Learning, etc.)
-
Y así sucesivamente.
No hay algoritmos directamente implementados en Scikit-learn. Aunque existen librerías dedicadas, en la mayoría de los casos es necesario reconstruir los algoritmos en Python (utilizando recuentos y estadísticas). Por lo tanto, el código queda fuera del alcance de este libro.
Sea cual sea el algoritmo elegido, hay dos casos más complejos que se tratarán por separado, salvo que se indique lo contrario:
-
Nuevos usuarios: como aún no han consumido nada, es difícil saber qué ofrecerles para empezar. En Netflix, por ejemplo, al crear un perfil, los usuarios tienen que elegir las series que les gustan para empezar a hacer sugerencias.
-
Nuevos contenidos: como nadie los ha consumido aún, es difícil saber a quién pueden gustar. En la mayoría de los casos, se propondrá aleatoriamente a los usuarios hasta que encuentre su «público».
2. Principales enfoques
a. Modelos...
Association
1. Definición
La tarea de asociar encuentra vínculos entre productos que pueden comprarse juntos, como las pastas y la salsa de tomate, generalmente en la forma pasta = > salsa de tomate (lo que indica que una compra de una pasta suele llevar a una compra de una salsa).
Una vez descubiertos estos vínculos, es posible actuar para aprovecharlos.
Por ejemplo, en una tienda, si existe un vínculo de compra entre dos productos A y B, es posible:
-
Ejecutar una promoción si el cliente compra A y B.
-
Colocar A y B muy cerca físicamente para que el cliente compre ambos.
-
Separar lo más posible A y B si la compra es verdaderamente acumulativa siempre, de modo que el cliente recorra el mayor número posible de estanterías.
-
Enviar una promoción de B a los compradores de A.
-
Y así sucesivamente.
El principal uso de los algoritmos de asociación es determinar qué productos se encuentran en la misma cesta de la compra (asociar compras).
Sin embargo, hay otros usos para esta tarea: en lugar de productos, puede buscar vínculos entre sucesos, por ejemplo, para comprender qué incidentes conducen a menudo a un accidente. También se utiliza en bioinformática para procesos complejos, detección de fraudes y minería web.
2. Evaluar algoritmos
La tarea de asociar produce reglas de la forma A = > B. Para evaluar la calidad de estas reglas se utilizan tres indicadores: soporte, índice de confianza y el «lift» (mejora de la confianza).
De hecho, cada parte, A y B, pueden contener varios elementos. Si se trata de A, significa que hay que sumar cada elemento para obtener la conclusión B. Si es B la que contiene varios elementos, significa que la regla tiene varias conclusiones.
He aquí un ejemplo de un conjunto de recibos de caja:
1. Piña - Plátano
2. Piña - Zanahoria - Fresa
3. Piña - Plátano - Fresa
4. Piña - Zanahoria - Fresa ...



