
Fundamentos de la inteligencia artificial
Lo que vamos a descubrir
En este primer capítulo, iniciaremos un viaje que le permitirá explorar las múltiples facetas de la inteligencia artificial, de la que hablaremos en este libro bajo su acrónimo "IA". Veremos una serie de definiciones, conceptos, palabras clave y demás terminología que le ayudarán a aprovechar al máximo el resto de este libro.
Empezaremos con la historia de la inteligencia artificial para entender los retos a los que nos enfrentamos hoy en día, y después pasaremos a la definición de inteligencia artificial "generativa".
Todo esto nos llevará rápidamente a una clasificación de los diferentes tipos de inteligencia artificial, examinando los enfoques y técnicas utilizados hoy en día para crear los llamados sistemas "inteligentes". Entre ellos se encuentran las redes neuronales, los árboles de decisión y muchos otros que tendrá el placer de descubrir aquí.
A continuación, nos adentraremos en un área que sin duda le resultará familiar, a saber, el aprendizaje automático que, como verá, es la piedra angular de la inteligencia artificial contemporánea.
También se hablará de las numerosas grandes familias de algoritmos de IA. No se asuste, no vamos a utilizar un enfoque matemático, sino que vamos a examinar las máquinas aprenden...
Historia de la inteligencia artificial
La historia de la inteligencia artificial ha estado marcada por innumerables momentos de descubrimiento, retos, fracasos, promesas, pero también hazañas que descubrirá a lo largo de este libro. Cada uno de estos elementos podría ser objeto de un libro por derecho propio.
Intentaremos ser mucho más concisos y en este primer capítulo exploraremos los hitos clave en la evolución de la inteligencia artificial que, como verá, aún está en pañales. Vamos a destacar los numerosos avances y proezas tecnológicas que han dado forma a esta disciplina compleja y sencillamente fascinante.
La historia de la inteligencia artificial comenzó poco después de la Segunda Guerra Mundial, en la década de 1950, lo que ya puede parecer bastante descabellado en una época en la que podríamos considerar que esta tecnología era emergente. Hablamos aquí de los cimientos de la inteligencia artificial, cuando un puñado de investigadores y científicos visionarios empezaron a imaginar la posibilidad de crear máquinas capaces de imitar la inteligencia humana, aunque fuera muy brevemente.
En 1956, pioneros de la informática, matemáticos y lingüistas se reunieron para investigar sistemas con capacidad para aprender de forma autónoma y resolver problemas considerados complejos. El término "inteligencia artificial" surgió de forma natural para describir esta nueva y prometedora capacidad de las máquinas.
Los primeros trabajos condujeron a la creación de programas informáticos para demostrar teoremas matemáticos, que sentaron las bases del aprendizaje automático. Al mismo tiempo, los investigadores desarrollaron nuevos lenguajes de programación informática capaces de manejar estructuras mediante símbolos y reglas de procesamiento para realizar una serie de tareas, conocidas como "estructuras simbólicas", que sentaron las bases de la comunicación entre máquinas y humanos.
Los años sesenta fue una época de audaz optimismo. Los pioneros de la inteligencia artificial soñaban con máquinas capaces...
La inteligencia artificial generativa
La inteligencia artificial ha evolucionado mucho más allá de simples programas que realizan tareas predecibles. Uno de los avances más intrigantes y cautivadores de la IA es su capacidad para crear, imaginar y generar contenidos originales. Esta fascinante faceta se conoce como "IA generativa".
La IA generativa abre nuevas perspectivas en la innovación, el arte, el entretenimiento e incluso en la resolución de problemas complejos.
Se basa en redes neuronales de aprendizaje profundo, como las redes generativas antagónicas GAN (Generative Adversarial Networks) y los Transformers, de los que hablaremos más adelante en este libro. Estas redes se entrenan con enormes volúmenes de datos y, una vez entrenadas, pueden generar datos nuevos y originales que se parezcan a aquellos con los que se entrenaron.
La IA generativa también puede crear imágenes realistas, composiciones musicales e incluso textos coherentes. Las GAN (redes generativas antagónicas) son famosas por su capacidad de generar imágenes que parecen producto de un artista humano, pero que en realidad sólo existen en código informático.
En cambio, los Transformers son excelentes generando texto, ya sean poemas, guiones de cine o entradas de blog. Volveremos sobre ello a lo largo del capítulo sobre DALL-E: aprovechar la creatividad de la IA.
Con todo ello, nuestra llamada...
Clasificación de la inteligencia artificial
El objetivo de la clasificación de la inteligencia artificial es ayudarle a comprender las diferentes categorías de sistemas desarrollados en este campo. A continuación, se presentan las cuatro áreas de clasificación que debe conocer.
1. La inteligencia artificial débil
La IA débil, también conocida por los nombres y acrónimos: de "Narrow AI" o "ANI", se refiere a los sistemas que han sido diseñados de antemano para realizar una tarea específica de forma inteligente. De hecho, se considera monotarea. La IA débil se define tanto por la simulación del comportamiento humano, como por las limitaciones que se le imponen con restricciones limitadas a la tarea que debe realizar. Es simplemente un experto en el campo que ha elegido.
A pesar de su apariencia, estos sistemas son bastante limitados en sus capacidades y no pueden generalizar su aprendizaje a otros ámbitos.
Algunos ejemplos comunes de IA débil:
-
sistemas de recomendación,
-
chatbots,
-
motores de búsqueda,
-
coches autónomos.
-
herramientas cartográficas,
-
asistentes virtuales,
-
sistemas de reconocimiento facial,
-
Siri, el asistente virtual de Apple.
Con esto queremos decir que la IA débil está orientada hacia un objetivo único y muy preciso, consistente en realizar tareas dedicadas y específicas.
2. La inteligencia artificial fuerte
Esta última también se conoce con los nombres y siglas...
Modelos de inteligencia artificial: machine learning
En este capítulo exploramos los distintos modelos de inteligencia artificial, empezando por el machine learning (ML) y sus algoritmos, la piedra angular de la IA.
A continuación, estudiaremos el procesamiento del lenguaje natural (NLP), que dota a nuestras máquinas de la capacidad de comprender el lenguaje humano, antes de pasar al “deep learning“(DL) y la visión por ordenador.
En este capítulo, descubriremos cómo cada uno de estos modelos contribuye al avance de la inteligencia artificial y allana el camino para aplicaciones que ya se pueden considerar revolucionarias.
Le recomendamos encarecidamente que revise cada uno de estos conceptos con regularidad para dominar las relaciones entre ellos.
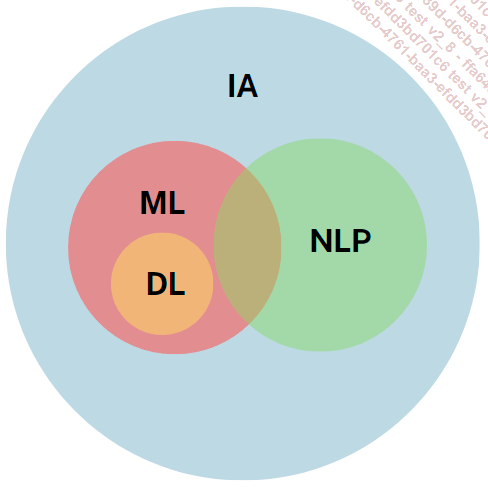
Modelos de IA
1. Aprendizaje automático aprendizaje automático
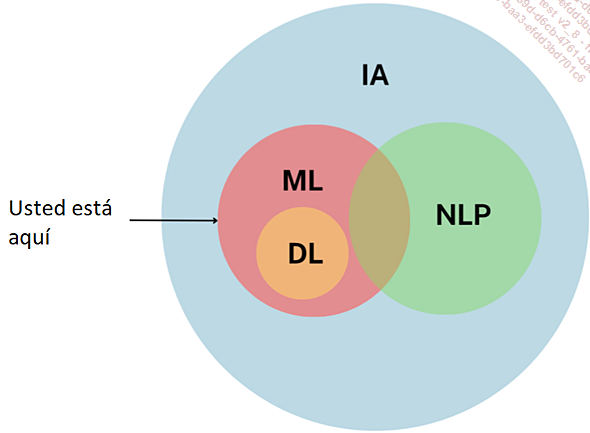
Aprendizaje automático
El machine learning, o ML por sus siglas en inglés, es una de las ramas más apasionantes de la inteligencia artificial, un tema que podría llenar un libro entero por derecho propio. Este revolucionario enfoque tecnológico permite a los "Data Scientists", comúnmente conocidos como científicos de datos, alimentar conjuntos de datos en algoritmos, dando a las máquinas la capacidad de aprender y tomar decisiones sin necesidad de programación informática previa.
En otras palabras, en lugar de seguir instrucciones estrictas, las máquinas pueden ahora adquirir conocimientos a partir de datos digitales preexistentes y mejorar con el tiempo, gracias al aprendizaje continuo y al creciente volumen de datos disponibles.
El machine learning se utiliza principalmente para identificar tendencias y similitudes, a menudo denominadas "patrones", ya sea en imágenes, palabras, estadísticas u otros ámbitos.
El objetivo subyacente es automatizar tareas y hacer predicciones basadas en datos anteriores.
He aquí algunos ejemplos de cómo se utiliza el ML:
-
Salud: detección de enfermedades.
-
El sector industrial: para supervisar sensores y averías.
-
Comercio: evolución de las ventas.
-
Turismo: precios basados en tendencias.
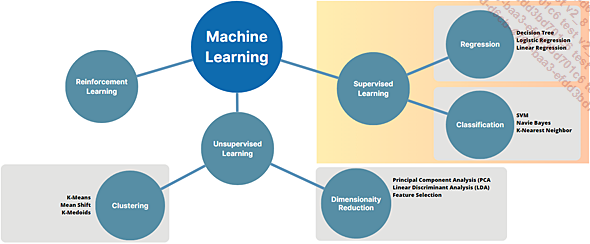
Discutiremos tres formas de paradigmas de machine learning:
-
El Aprendizaje Supervisado (Supervised Learning).
-
El Aprendizaje No-Supervisado (Unsupervised Learning).
-
El Aprendizaje por Refuerzo (Reinforcement Learning).
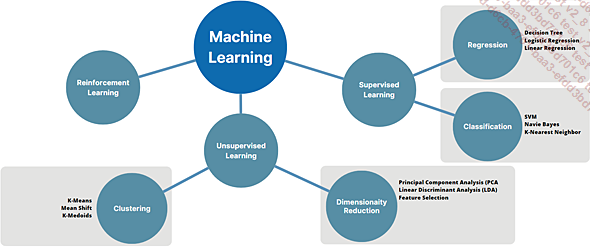
Paradigmas y algoritmos de machine learning
2. Aprendizaje supervisado (Supervised Learning)
El aprendizaje supervisado es un enfoque destinado a crear modelos "predictivos" para anticiparse a las necesidades de una empresa, por ejemplo. En este contexto, la máquina ya tiene las respuestas esperadas y nuestro papel es guiar su adquisición de conocimientos, proporcionándole ejemplos de preguntas y respuestas.
En el aprendizaje supervisado, es imprescindible especificar tanto los datos de entrada como los resultados esperados. El objetivo del aprendizaje supervisado es crear un modelo capaz de predecir resultados correctos para datos nuevos, no vistos previamente.
Pongamos un ejemplo concreto para ilustrar el concepto de aprendizaje supervisado. Imaginemos que un Data Scientist quiere entrenar un algoritmo para determinar si una imagen contiene un panda, un oso o un pingüino. En el aprendizaje supervisado, asigna una "etiqueta" a cada imagen del conjunto de datos de entrenamiento, especificando si la imagen contiene uno de estos animales o no.
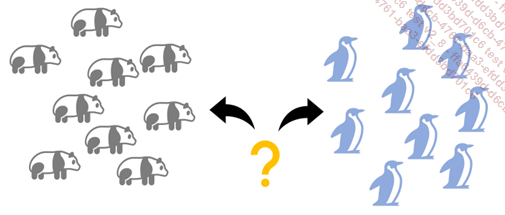
Aprendizaje supervisado
Los datos utilizados en el aprendizaje supervisado para el entrenamiento se etiquetan con los valores de salida esperados. Por ejemplo, en la clasificación de imágenes, cada imagen se etiqueta con la categoría a la que pertenece.
La eficacia del modelo se evalúa comparando sus predicciones con los valores reales, a menudo utilizando métricas como la exactitud, la precisión, el recuerdo, etc.
3. Aprendizaje no supervisado (Unsupervised Learning)
Al igual que el aprendizaje supervisado, el aprendizaje no supervisado se entrena con datos que no tienen etiqueta (un panda no es un panda, un pato aún no es un pato, etc.). Esta vez, nuestro modelo de aprendizaje se basará en las similitudes, agrupándolos en conjuntos y subconjuntos que llamaremos "Clustering".
El objetivo del aprendizaje no supervisado es realizar agrupaciones para identificar grupos de datos similares o reducir la dimensionalidad para visualizar o analizar los datos con mayor eficacia.
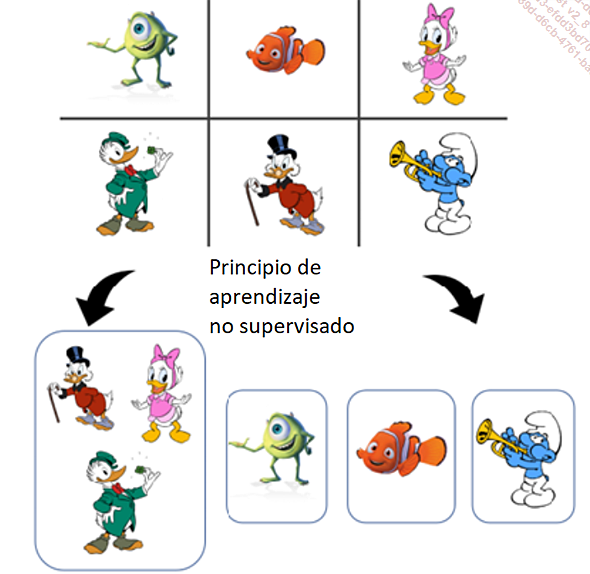
El principio del aprendizaje no supervisado
El principio de asociación es complementario a la agrupación, con la detección de probabilidades, por ejemplo, los animales con pico amarillo llevan normalmente sombrero. Se trata de un fenómeno de probabilidad de co-ocurrencia, que permite crear nuevos grandes grupos de datos.
En el aprendizaje no supervisado, los datos utilizados no están etiquetados con valores de salida específicos. El algoritmo trata de descubrir información oculta en los datos.
La evaluación del aprendizaje no supervisado puede ser más compleja, ya que no hay respuestas correctas predefinidas.
El aprendizaje supervisado utiliza datos etiquetados para predecir resultados, mientras que el aprendizaje no supervisado trata de descubrir estructuras o patrones en datos no etiquetados.
4. Aprendizaje por refuerzo (Reinforcement...
Los principales algoritmos supervisados (para la predicción de valores)
Algoritmos supervisados
1. Algoritmo de regresión: Árbol de decisión (Decision Tree)
El método del árbol de decisión es una ayuda para la toma de decisiones y la exploración de datos, ilustrada en forma de diagrama de árbol. Cada rama del árbol representa una serie de pruebas para predecir un resultado, con decisiones tomadas en cada extremo. Los datos se dividen en subgrupos en cada prueba, y las predicciones se basan en las medias de estos subgrupos. Por ejemplo, en el contexto de la estimación del salario de un empleado de una empresa de venta online en función de la antigüedad y el número de casos atendidos, las pruebas sucesivas del árbol darán lugar a predicciones. El árbol puede dividir a los empleados en función de su antigüedad, calcular el salario medio de cada grupo y, a continuación, predecir el salario de un empleado concreto basándose en estos promedios. El árbol de decisión es una herramienta de aprendizaje supervisado, en la que el algoritmo utiliza datos pasados para hacer predicciones sobre datos nuevos mediante un enfoque de ramas y pruebas.
2. Algoritmo de regresión: Regresión logística (Logistic Regression)
Los polinomios se utilizan para modelizar relaciones matemáticas en diversos campos, como la física, la economía y la ingeniería. También se suelen utilizar para resolver ecuaciones y realizar cálculos matemáticos....
Redes neuronales (Neural NetWorks)
Acabamos de explorar los fundamentos del machine learning y sus diversos sistemas de aprendizaje. Ahora es el momento de adentrarnos en otro componente esencial de la inteligencia artificial contemporánea: el mundo de las redes neuronales. Este elemento puede parecer complicado de entender, pero intentaremos que su comprensión sea sencilla.
¿Qué es una red neuronal? ¿Está inspirada en el funcionamiento del cerebro humano? La respuesta es sí.
En efecto, las redes neuronales son modelos inspirados en el funcionamiento de nuestro cerebro humano. Al igual que nuestro cerebro está formado por miles de millones de células llamadas "neuronas"; una red neuronal artificial se compone de pequeñas piezas llamadas "neuronas artificiales".
Están diseñadas para hablar entre ellas con el fin de aprender continuamente y resolver problemas de una forma totalmente similar a nuestro propio sistema nervioso. Cada neurona intercepta información, la mezcla y luego la envía a otras neuronas. Trabajando juntas, estas neuronas artificiales pueden aprender multitud de cosas, como por ejemplo a distinguir un animal en una imagen.
Por ejemplo, podemos establecer un paralelismo con el aprendizaje que experimentamos de niños, cuando aprendíamos a reconocer formas geométricas. Nuestros padres nos enseñaron a separar formas como cuadrados y círculos. Así, poco a poco, nuestros jóvenes cerebros empezaron a entender la diferencia entre estas formas. Pues bien, las redes neuronales funcionan de la misma manera.
Las redes neuronales son un método de aprendizaje automático.
El aprendizaje de las redes neuronales se podría comparar al de una persona normal que aprende a tocar un nuevo instrumento musical. Al principio es complejo, pero cuanto más practicamos, más expertos nos volvemos y, para ello, las redes neuronales "escuchan" enormes cantidades de ejemplos para aprender y mejorar.
En cuanto a la inteligencia artificial...
Procesamiento del lenguaje natural NLP
En este capítulo, le presentamos una nueva rama tan apasionante como las anteriores: el Procesamiento del Lenguaje Natural (Natural Language Processing o su acrónimo NLP).
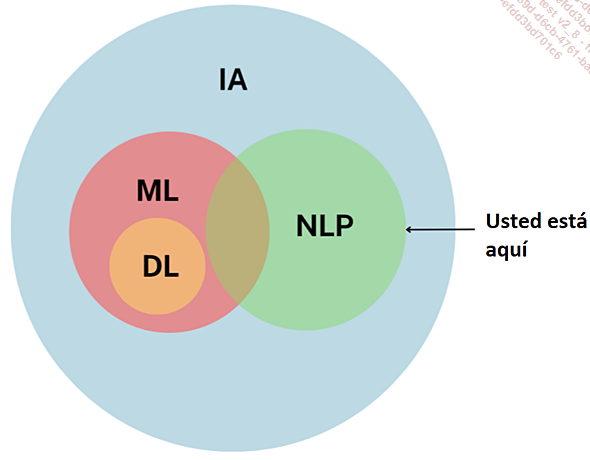
NLP
La razón de ser de la NLP es permitir a nuestras máquinas entender y manipular el lenguaje humano, ¡nada menos!
Como dato interesante, el NLP se remonta a los primeros tiempos de la informática, en los años 50, pero su importante desarrollo se ha acelerado en las últimas décadas gracias a los avances tecnológicos en inteligencia artificial.
En aquella época, los primeros trabajos se centraban principalmente en la traducción automática. Una década más tarde, en los años 60, aparecieron nuevos enfoques que permitieron añadir reglas gramaticales a la traducción automática.
En 1964, Joseph Weizenbaum (https://es.wikipedia.org/wiki/ELIZA) creó el primer robot conversacional, Eliza.
En los años 90, el enfoque estadístico también ganó popularidad. Los investigadores utilizaron modelos basados en la estadística y la probabilidad para resolver las principales carencias del NLP, que eran el reconocimiento del habla y la traducción automática.
En la última década, el uso de redes neuronales profundas ha revolucionado el NLP. Los modelos de procesamiento del lenguaje basados en el aprendizaje profundo han permitido alcanzar un rendimiento absolutamente notable en muchas tareas, como la traducción automática, la generación de textos y el análisis de sentimientos.
En la actualidad, las dos tareas principales del NLP son:
-
la comprensión del lenguaje natural: en inglés Natural Language Understanding (NLU),
-
la generación del lenguaje natural: en inglés Natural Language Generation (NLG).
1. Comprensión del lenguaje natural (NLU)
La comprensión del lenguaje natural (NLU) es el arte de descifrar el significado oculto en un texto o conversación, mucho...
El deep learning: aprendizaje profundo
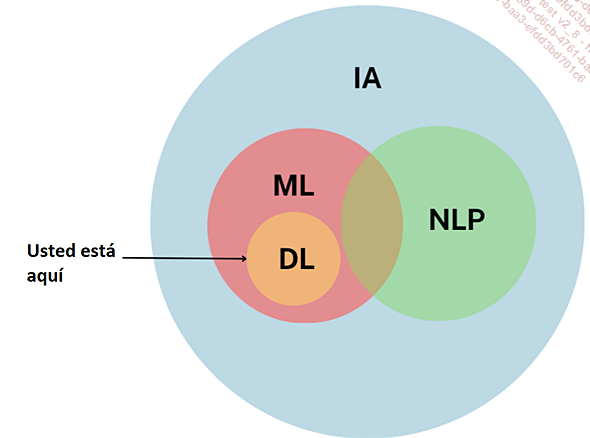
Deep learning
El deep learning es una rama del aprendizaje automático (machine learning) de la que hablamos al principio de este capítulo. También lo reconocerá como "aprendizaje profundo".
La razón de ser del deep learning es permitir que las máquinas aprendan de forma autónoma a partir de cantidades masivas de datos.
Su objetivo último es resolver problemas complejos.
1. Historia del deep learning
La historia del deep learing es una fascinante epopeya tecnológica que ha visto evolucionar y crecer esta rama de la inteligencia artificial, a lo largo de las décadas. A continuación, se muestra una retrospectiva de los momentos clave de la historia del deep learing:
En la década de 1940, investigadores como Warren McCulloch y Walter Pitts llevaron a cabo los primeros trabajos en el campo de las redes neuronales, que siguen constituyendo la base del deep learing.
Sus trabajos sentaron las bases teóricas de las redes neuronales como modelo matemático para simular la función cerebral.
En las décadas siguientes, la inteligencia artificial realizó numerosos avances, pero las redes neuronales permanecieron en gran medida inactivas.
En su lugar, los investigadores han favorecido otros enfoques, como los árboles de decisión y las máquinas de vectores de soporte. En ingles Support Vector Machines (SVM), para resolver problemas de aprendizaje automático.
El deep learning experimentó un repunte a principios de la década de los años 2000 gracias a los revolucionarios avances tecnológicos y teóricos. El aumento de la potencia de cálculo, sobre todo con el uso de GPU (unidades de procesamiento gráfico), permitió entrenar las redes neuronales profundas con mucha más rapidez.
Los investigadores también han desarrollado técnicas de entrenamiento...
Conclusión
En este primer capítulo hemos examinado los fundamentos de la inteligencia artificial, un campo fascinante que sigue configurando nuestro mundo de manera profunda.
A partir de la fascinante historia de la IA, desde sus modestos inicios hasta sus espectaculares avances, pasando por las distintas clasificaciones de la inteligencia artificial, hemos explorado los aspectos fundamentos principales -ciertamente largos pero, una vez más, esenciales- que sustentan este campo en constante evolución.
También nos adentramos en el cautivador mundo de la inteligencia artificial generativa, donde las máquinas son capaces de crear nuevas realidades artísticas y funcionales.
También hablamos del machine learning, con sus potentes algoritmos que permiten a los ordenadores aprender de los datos y de las redes neuronales, que han revolucionado la forma de abordar tareas complejas como la visión por ordenador y el procesamiento del lenguaje natural.
El capítulo también explora el mundo del deep learning, destacando cómo las redes neuronales profundas han abierto nuevas y apasionantes perspectivas para la IA, especialmente en el reconocimiento de imágenes y la comprensión del lenguaje natural.
Mientras nos preparamos para sumergirnos en las aplicaciones de la IA en el mundo real en el capítulo Etapas de la creación de una IA, recordemos que estos fundamentos...


