
Las bases de la arquitectura Oracle
Presentación general
1. Nociones de instancia y base de datos
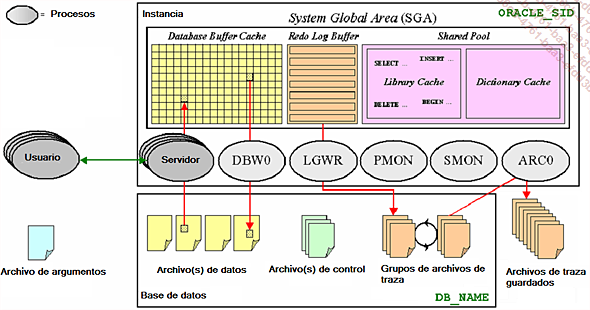
Un servidor Oracle tiene dos elementos distintos, la instancia y la base de datos.
La base de datos se compone de un conjunto de archivos físicos, que fundamentalmente contienen los datos. La instancia se compone de una estructura de memoria compartida y un conjunto de procesos. Estos dos elementos están íntimamente relacionados, pero se deben diferenciar correctamente.
De manera imaginaria, es posible considerar que la instancia representa una aplicación (por ejemplo, Microsoft Word) y la base de datos es el documento (por ejemplo, un documento Microsoft Word); para poder acceder a la base de datos (el equivalente al documento Microsoft Word), hay que abrirlo con una instancia Oracle (el equivalente a la aplicación Microsoft Word).
Una instancia solo se puede abrir en una base de datos a la vez y, en la gran mayoría de los casos, una base de datos solo se abre por una única instancia. Sin embargo, con la implementación de la opción Real Application Clusters (RAC), una base de datos se puede abrir en varias instancias, ubicadas en distintos nodos de un clúster de servidores; esta opción RAC es interesante para la alta disponibilidad.
La instancia usa un archivo de argumentos durante su arranque para configurarse y vincularse con la base de datos.
Además de los procesos de la instancia, existen procesos de usuario, correspondientes a la aplicación utilizada por el usuario para conectarse a la base de datos (SQL*Plus, un paquete de software, un software específico, etc.). En una arquitectura cliente/servidor, estos procesos de usuario se ubican en el puesto del usuario y se comunican con el servidor a través de la red gracias a la capa Oracle Net (consulte el capítulo Oracle Net para una presentación de Oracle Net).
2. La base de datos...
La base de datos
1. Archivo de control
El archivo de control contiene la información de control de la base de datos:
-
el nombre de la base de datos;
-
la fecha y hora de creación de la base de datos;
-
la ubicación de los demás archivos de la base de datos (archivos de datos y de traza);
-
el número de secuencia actual de los archivos de traza;
-
información de los puntos de control (checkpoint);
-
etc.
Oracle actualiza automáticamente el archivo de control durante cada modificación de la estructura de la base de datos (adición o movimiento de un archivo, por ejemplo). Oracle determina el tamaño del archivo de control.
Cuando se ejecuta una instancia para abrir una base de datos, el archivo de control es el primer archivo que se abre. Permite a la instancia localizar y abrir el resto de archivos de la base de datos. Si no se puede encontrar el archivo de control (o éste se encuentra dañado), la base de datos no se puede abrir, incluso si está el resto de archivos de la base de datos (la instancia permanece en estado NOMOUNT - consulte el capítulo Inicio y parada). Hay diferentes escenarios de restauración disponibles, en función de la situación (presencia o no de una copia de seguridad del archivo de control, principalmente), para volver a arrancar la base de datos, pero se trata de escenarios relativamente complejos.
Por razones de seguridad, se aconseja multiplexar el archivo de control, es decir, que Oracle administre varias copias en espejo (multiplexado). Técnicamente, es posible crear una base de datos con un único archivo de control, pero es muy aconsejable utilizar varias copias incluso si el servidor solo tiene un disco (esto reduce la posibilidad de eliminación accidental).
Se pueden especificar varios archivos de control durante la creación de la base de datos (capítulo Creación de una nueva base de datos), o más adelante (capítulo Archivos de control y de traza).
2. Archivos de traza
Los archivos de traza (redo log) registran todas las modificaciones realizadas a la base de datos. Se organizan en grupos escritos de manera circular; la información guardada se elimina periódicamente.
Los archivos de traza se utilizan para la restauración de la instancia después de una parada anormal y para recuperar los medios si se pierde o se daña...
La instancia
1. La SGA
a. Descripción general
La SGA (System Global Area) es una zona de memoria compartida por los diferentes procesos de la instancia.
La SGA se asigna al inicio de la instancia y se libera durante su parada. Se dimensiona en base a un conjunto de argumentos definidos en el archivo de argumentos.
Desde la versión 9 de Oracle la SGA se puede redimensionar en caliente. Desde la versión 10 de Oracle, algunas estructuras de la SGA se pueden administrar automáticamente (consulte la sección La gestión de la memoria, en este capítulo).
El tamaño máximo de la SGA se limita con el argumento SGA_MAX_SIZE.
La SGA tiene las siguientes estructuras:
-
Database Buffer Cache: caché de datos;
-
Redo Log Buffer: memoria RAM para el registro de las modificaciones efectuadas en la base de datos;
-
Shared Pool: zona de compartición de las consultas (Library Cache), caché del diccionario de datos Oracle (Dictionary Cache) y caché para el resultado de consultas SQL o de las funciones PL/SQL (Result Cache, que apareció en la versión 11);
-
Java Pool: memoria utilizada por la máquina virtual Java integrada;
-
Large Pool: zona de memoria opcional, utilizada por diferentes procesos, en configuraciones particulares;
-
Streams Pool: zona de memoria utilizada por la funcionalidad Streams (funcionalidad que permite que la información circule entre procesos).
La SGA también contiene una estructura llamada "SGA fija", que contiene la información del estado de la base de datos, de la instancia y los bloqueos. Esta SGA fija no la dimensiona el DBA; su tamaño es bajo (varios centenares de KB).
En Oracle Enterprise Manager, en español, Oracle utiliza la siguiente terminología:
|
Database Buffer Cache |
cache tampón |
|
Shared Pool |
pool compartido |
|
Java Pool |
pool java |
|
Large Pool |
zona de memoria LARGE POOL |
Generalmente, cuando más grande es la SGA, mejor es el rendimiento... teniendo en cuenta que la SGA se asienta en memoria física
b. El Shared Pool
El Shared Pool está compuesto principalmente de tres estructuras:
-
la Library Cache;
-
la Dictionary Cache;
-
la Result Cache.
La Library Cache contiene la información de las sentencias SQL y PL/SQL que se han ejecutado recientemente:
-
el texto de la sentencia;
-
su versión analizada;
-
el plan de ejecución.
La Dictionary Cache contiene la información...
El administrador de la base de datos
1. Principales tareas
Las principales tareas del administrador de la base de datos (DBA) son las siguientes:
-
instalación de los productos;
-
creación/inicio/parada de las bases de datos;
-
gestión de las estructuras de almacenamiento;
-
gestión de los usuarios (y sus permisos);
-
copia de seguridad/restauración.
2. Cuentas Oracle de administración
Después de la creación, una base de datos Oracle siempre contiene dos cuentas con permisos de administrador:
-
SYS (contraseña por defecto: change_on_install);
-
SYSTEM (contraseña por defecto: manager).
SYS es el propietario del diccionario de datos; SYSTEM puede ser propietario de las tablas adicionales utilizadas por las herramientas Oracle.
Desde Oracle9i Release 2, estas contraseñas por defecto se pueden cambiar durante la creación de la base de datos.
Estas cuentas se pueden utilizar indistintamente para la administración actual (gestión de los usuarios, del almacenamiento, etc.) solo cuando la base de datos está arrancada.
Se necesita un permiso adicional particular (SYSDBA o SYSOPER) para realizar algunas operaciones (inicio, parada, etc.). En la versión 12, Oracle ha introducido un nuevo permiso, SYSBACKUP, que solo contiene los permisos necesarios para realizar copias de seguridad y restauraciones. Este nuevo permiso permite separar mejor los roles y responsabilidades en una empresa entre el administrador de la base de datos, que necesita todos los permisos, y un operador de copia de seguridad, que necesita permisos más restrictivos para realizar su trabajo. Adicionalmente, la activación de estos permisos necesita un mecanismo de autentificación particular, ya que la base de datos puede no estar disponible. Esta autentificación se realiza por el sistema operativo o por un archivo de contraseñas.
En el capítulo Gestión de usuarios y sus permisos veremos que la noción de "DBA" se corresponde con un rol (conjunto de permisos agrupados bajo un nombre) que se puede asignar a una cuenta de usuario.
3. Identificación privilegiada SYSDBA, SYSOPER y SYSBACKUP
a. Por el sistema operativo
Para utilizar la autentificación por el sistema operativo, debe introducir el usuario deseado del sistema operativo en un grupo de permisos especial mencionado en la documentación Oracle...
El diccionario de datos
1. Presentación
El diccionario de datos es un conjunto de tablas y vistas que dan información sobre el contenido de una base de datos:
-
las estructuras de almacenamiento;
-
los usuarios y permisos;
-
los objetos (tablas, vistas, índices, procedimientos, funciones, etc.).
-
etc.
El diccionario de datos pertenece a SYS y se almacena en el tablespace SYSTEM. Se crea durante la creación de la base de datos y Oracle lo actualiza automáticamente, cuando se ejecutan sentencias SQL DDL (Data Definition Language) (CREATE, ALTER, DROP).
Para utilizarlo, es suficiente con realizar consultas usando sentencias SELECT. Salvo excepciones, toda la información se almacena en mayúsculas en el diccionario de datos; téngalo en cuenta cuando escriba sus cláusulas WHERE.
El diccionario de datos se carga en memoria en la parte Dictionary Cache de la Shared Pool y Oracle lo utiliza de manera interna para procesar las consultas.
El diccionario de datos se crea durante la creación de la base. Desde un punto de vista práctico, Oracle no documenta las tablas del diccionario de datos propiamente dichas, por lo que son difíciles de utilizar. Por el contrario, gracias a los scripts proporcionados por Oracle, es posible crear vistas (y sinónimos públicos) que sí están documentadas y permiten explotar el diccionario de datos de manera efectiva; esta etapa de creación de una base de datos, se presentará en el capítulo Creación de una nueva base de datos.
Hay dos grandes grupos de tablas/vistas en el diccionario de datos:
-
las tablas y vistas estáticas;
-
las tablas y vistas dinámicas de rendimiento.
Las tablas y vistas estáticas se basan en tablas reales almacenadas en el tablespace SYSTEM. Son accesibles solo cuando la base de datos está abierta "completamente". Las tablas y vistas dinámicas de rendimiento no se basan en tablas reales, sino en la información en memoria o extraída del archivo de control. Sin embargo, se acceden como tablas/vistas reales y dan información del funcionamiento de la base de datos, fundamentalmente del rendimiento. La mayor...
