
Restringir y delegar el acceso
Objetivos del capítulo y requisitos previos
Este capítulo presenta cómo implementar una estrategia de limitación de consumo de recursos en un clúster. Esta estrategia se basa en varios mecanismos:
-
Uso de espacios de nombres.
-
Establecer límites en estos espacios de nombres.
-
Gestión de permisos de usuario en un clúster (con partición por espacio de nombres).
-
Implementación de un mecanismo de autenticación externo (basado en el protocolo OAuth2).
Para cada uno de estos diferentes problemas, se expondrán soluciones.
Una parte final se dedicará a la creación de cuentas de acceso técnico. Permiten actualizar o lanzar trabajos desde herramientas externas (CI/CD, planificadores externos, etc.).
Configurar cuotas
1. Origen de la necesidad
Hasta ahora, los recursos creados no tenían necesariamente espacios de nombres o restricciones de consumo. En el caso de un clúster utilizado por varios equipos, una buena práctica es separar las diferentes aplicaciones o entornos de aplicaciones utilizando espacios de nombres y adjuntarles medidas de seguridad.
En Kubernetes, estas medidas de seguridad adoptan la forma de cuotas y se pueden definir mediante dos tipos de límites:
-
Limitaciones individuales en contenedores/pods (LimitRange).
-
Limitaciones de consumo de recursos acumulados en un espacio de nombres (ResourceQuota).
A continuación, se muestran algunos ejemplos de definición de limitación:
-
Limitación de consumo de CPU o memoria por pod o global.
-
Limitación del número de incidencias de objetos (pods, despliegue, servicio).
-
Reglas entre el consumo mínimo y máximo de un recurso.
Tenga en cuenta que establecer cuotas de recursos (ResourceQuota) en un espacio de nombres lo obligará a establecer limitaciones a nivel de los contenedores. Un contenedor/pod sin estas limitaciones no se puede desplegar ahí.
2. Cuotas por defecto en un espacio de nombres
a. Crear un espacio de nombres
Para otras operaciones, se utilizará el espacio de nombres test. Por tanto, la primera operación consistirá en crearlo:
$ kubectl create ns test Los objetos LimitRange y ResourceQuota se adjuntan a un espacio de nombres. Se pueden vincular de varias maneras:
-
A nivel del campo de metadata --> namespace.
-
Especificando la opción -n seguida del espacio de nombres durante el lanzamiento de kubectl.
-
Usando el comando kubens.
Para el resto de los ejercicios, cambie al espacio de nombres test:
$ kubens test b. Estructura de un objeto LimitRange
Un objeto LimitRange es un primer tipo de cuota. Si se crea un pod o un contenedor sin limitación, este objeto definirá los valores predeterminados.
Estas limitaciones son las mismas que se analizan en el capítulo Ciclo de vida de un contenedor en Kubernetes, a saber:
-
Asignación de recursos de CPU o memoria (campos requests).
-
Limitación de recursos de CPU o memoria (campos limits).
La declaración de un objeto LimitRange se realiza utilizando los siguientes elementos:
-
Un encabezado clásico con el tipo (kind), la versión (apiVersion) y los metadatos...
Autenticación y autorización
1. Origen de la necesidad
La sección anterior se dedicó a implementar restricciones de acceso a nivel de espacio de nombres. Sin embargo, todos los accesos se realizaron con el mismo identificador.
Así, el archivo Kubeconfig se convierte en un recurso crítico, como una contraseña de root o una clave privada SSH.
Si bien en un equipo pequeño este tipo de incidente sigue siendo aceptable, en una organización más grande esta situación puede suponer un problema.
Los usuarios pueden ser autenticados usando varios mecanismos:
-
autorizando el acceso anónimo,
-
por certificados de cliente x509,
-
por archivos de definición de usuario estáticos,
-
por usuarios autenticados usando OAuth2,
-
por proxy de autenticación.
Algunos de estos accesos se basan en la configuración del servidor API de Kubernetes mediante el uso de opciones de arranque o la emisión de certificados, generados vía la infraestructura de clave privada del clúster (Private Key Infrastructure).
En adelante, se tratarán los siguientes mecanismos:
-
Implementación de acceso anónimo.
-
Autenticación por certificado.
-
Autenticación por mecanismo externo (basado en OAuth2).
Finalmente, el lector abordará el uso de cuentas de servicio (objeto ServiceAccount). Este mecanismo se debe utilizar en el caso de llamadas externas, como cuando se emplean autómatas, por ejemplo.
2. Requisitos previos
Los ejercicios que siguen se basarán en la modificación de las opciones de inicio de la API de Kubernetes o la emisión de certificados basados en la clave del clúster. Naturalmente, este ejercicio no se puede realizar en un clúster gestionado debido a la imposibilidad de acceder a los certificados internos del clúster o a las opciones de inicio de la API.
Por lo tanto, es imprescindible que el clúster haya sido creado por usted (usando Kubespray o k3s, pero también con otros métodos como Kubeadm, Kops, Minikube, etc.) o, en todo caso, que disponga de los accesos necesarios. En adelante, el ejercicio se realizará en un clúster Minikube.
Otro requisito previo es que parte de los ejercicios demandará generar certificados utilizando OpenSSL. Por lo tanto, debe tenerlo localmente en su ordenador.
Los ejercicios no requieren necesariamente...
Mecanismos de autenticación externos
1. Presentación del mecanismo
En Kubernetes, no existe un tipo para representar a un usuario: se referencian directamente como un identificador (clemente, admin@mi-empresa.com) o un grupo (administrador, intranet, etc.).
En el resto del capítulo, se tratará el acceso mediante identificadores OAuth2.
El acceso mediante identificadores OAuth2, es bastante parecido a lo que se ha hecho en el capítulo Securizar el acceso a las aplicaciones. El ejercicio se realizará con las API de Google, pero las instrucciones son completamente aplicables a las de GitHub o cualquier proveedor de identificadores Oauth2.
2. Comunicación entre el proveedor OAuth2 y el clúster
La autenticación entre el clúster y el proveedor de identificadores se basa en el protocolo OpenID Connect (una extensión popular del protocolo OAuth2, compatible con Google o Azure).
La principal diferencia es la presencia de un campo que contiene un token de identificación de tipo JWT (JSON Web Token). Este token se utiliza para la autenticación del usuario y también puede contener campos adicionales, como la dirección de correo electrónico del usuario. Asimismo, está firmado por el proveedor de identidad.
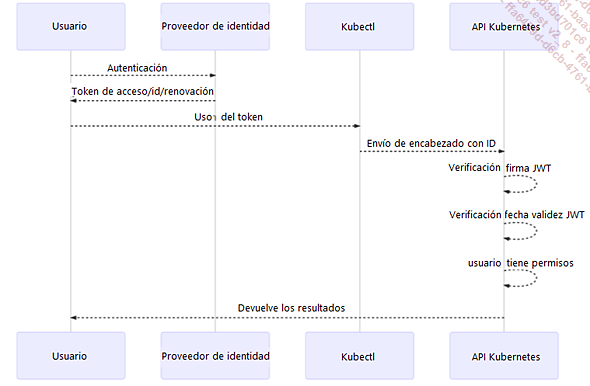
Diagrama de comunicación entre el clúster de Kubernetes y el proveedor de Oauth2
3. Crear los identificadores
Primera etapa: crear identificadores de cliente para OAuth2. Esta operación se realiza desde la consola de Google (o cualquier otro proveedor de identidad).
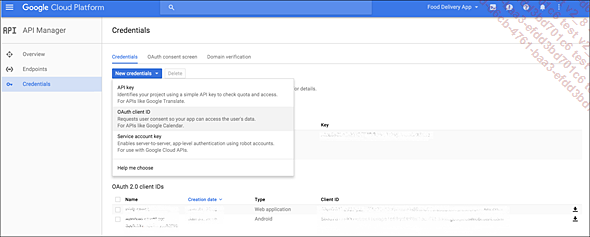
Creación del identificador ID client OAuth
En la siguiente pantalla, elija el tipo de aplicación Other.
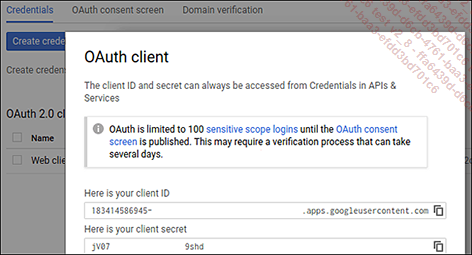
Recuperación de los identificadores después de crear el identificador ID client OAuth
En la última pantalla, recupere el ID y el secreto del cliente para usarlos con posterioridad.
4. Modificar las opciones de inicio (Minikube)
La modificación de las opciones de inicio del clúster sigue el mismo procedimiento que la habilitación del acceso anónimo.
Abra una conexión en Minikube:
$ minikube ssh Escale como root:
$ sudo su - Mueva el archivo kube-apiserver.yaml a un directorio de trabajo:
$ mv /etc/kubernetes/manifests/kube-apiserver.yaml /tmp/. Edite las opciones de inicio del contenedor de la API de Kubernetes para añadir las siguientes opciones:...
Implantar cuentas de servicio
1. Contexto
Una buena manera de interactuar con un clúster de Kubernetes es hacerlo a través de una cuenta de servicio. Esta necesidad, generalmente, se justifica al implementar autómatas (despliegue continuo, compilación, auditoría de seguridad, monitoreo, etc.).
Sin embargo, se debe tener mucho cuidado con el uso de este tipo de acceso. El token de autenticación da licencia para realizar todas las operaciones permitidas por el usuario técnico.
Posteriormente, el lector creará una cuenta de servicio accesible desde fuera del clúster.
2. Crear la cuenta de servicio
Una cuenta de servicio se crea utilizando un objeto de tipo ServiceAccount.
A continuación, se muestran los campos obligatorios:
-
El campo apiVersion (v1) y kind (ServiceAccount).
-
El campo metadata con dos subcampos:
-
El campo name con el valor cicd.
-
El campo namespace con valor default.
A continuación, la declaración correspondiente:
apiVersion: v1
kind: ServiceAccount
metadata:
name: cicd
namespace: default Guarde esta definición en el archivo cicd-account.yaml y aplique su declaración en el clúster de Kubernetes:
$ kubectl apply -f cicd-account.yaml Un método alternativo es usar el comando kubectl create seguido de estas opciones:
-
El tipo de objeto que se va a crear (serviceaccount).
-
El espacio de nombres que se va a usar (--namespace default).
-
El nombre del objeto que se va a crear: cicd.
A continuación, se muestra el comando correspondiente:
$ kubectl create serviceaccount --namespace default cicd La elección de cualquiera de los métodos depende del lector. Sin embargo, se prefiere el primer método, ya que es más fácil almacenar la declaración de la cuenta en un repositorio Git.
3. Asignación de los permisos de administrador de la cuenta de servicio
La cuenta ahora debe estar asociada al rol cluster-admin. Este enlace se realizará mediante un objeto ClusterRoleBinding. Dicho objeto está estructurado de la siguiente manera:
-
Los encabezados apiVersion (rbac.authorization.k8s.io/v1) y kind (ClusterRoleBinding).
-
El campo metadata para especificar el nombre del objeto.
-
Un registro roleRef que permite especificar el rol que queremos asignar al usuario. Este registro contendrá los siguientes campos:
-
El campo apiGroup...