
Un poco más sobre la Web
Introducción
Ya hemos abordado en el capítulo dedicado a la red una parte dedicada a las bases de la Web. Vamos a suponer que esta parte ya se ha comprendido con el fin de profundizar un poco en algunos aspectos de la Web.
Muchas aplicaciones especializadas para la Web en seguridad informática utilizan el lenguaje Python. Por citar solo algunas, tenemos sqlmap, W3af, wapiti...
Vamos a insistir aquí en las técnicas de fuerza bruta y de parsing HTML. Veremos cómo crear diferentes herramientas útiles para los escenarios de ataque en la web.
Recordemos lo básico
La realmente útil librería urllib2 nos será indispensable para continuar. Resumamos lo que hemos visto en el capítulo Red: la librería Scapy.
import urllib2
body=urllib2.open("http://www.ediciones-eni.com")
print body.read()
Acabamos de realizar una petición GET a un sitio web. Esto nos devolverá un objeto archivo que podremos leer.
Nos gustaría poder definir cabeceras específicas, crear peticiones POST, utilizar las cookies...
Vamos a crear la misma consulta que antes pero utilizando la clase request y definiendo un User-Agent HTTP personalizado.
import urllib2
url = "http://www.ediciones-eni.com"
headers = {}
headers['User-Agent'] = 'Googlebot'
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
print response.read()
response.close()
Obtenemos la respuesta siguiente:
└─> python web_header_agent.py
<!DOCTYPE html>
<html id="ctl00_html" xmlns="http://www.w3.org/1999/xhtml" lang="es">
<head id="ctl00_Head1"><title>
Ediciones ENI es editor de libros informáticos
</title>
<a href="https://plus.google.com/112326652557810849753"...Mapping de sitios web
El desarrollo de los CMS (Content Management System) como Drupal, WordPress o Joomla ha convertido la creación de sitios web en algo trivial. Incluso las empresas recurren a estos CMS.
Cuando las personas que instalan estos CMS no toman las precauciones necesarias para securizar su sitio, es muy fácil para un atacante obtener acceso no autorizado al servidor web.
Podemos obtener de forma gratuita el código fuente de estas diferentes herramientas CMS e instalarlas en local para determinar la estructura de directorios y el nombre de los archivos instalados. Seremos capaces, entonces, de crear un escáner que recorrerá todos los archivos y directorios en el sitio remoto.
Vamos a tratar de crear este escáner utilizando para ello el objeto Queue para crear una aplicación rápida y multihilo.
#--*--coding:utf-8--*--
import Queue, threading, os, urllib2
threads=10
target = "http://www.ediciones-eni.com"
directory="/home/javier/Descargas/joomla-3.1.1"
filters=[".jpg",".gif",".png",".css"]
os.chdir(directory)
web_paths=Queue.Queue()
for r,d,f in os.walk("."):
for files in f:
remote_path="%s/%s" % (r,files)
if remote_path.startwith("."): ...Fuerza bruta de carpetas o de ubicación de archivos
En la sección anterior, deberíamos tener información relevante sobre el objetivo, como el CMS utilizado, etc. y deberíamos instalar este CMS en nuestro equipo para conocer los archivos y directorios.
En muchos casos, no tendremos en nuestro poder toda la información. Tendremos que utilizar una herramienta de fuerza bruta para intentar recopilar la información importante (o no).
Vamos a fabricar una herramienta sencilla que utilizará un diccionario y tratará de descubrir los directorios y archivos que pueden ser leídos del sitio web objetivo.
Como antes, utilizaremos un pool de threads para tratar de descubrir (de forma agresiva) el contenido.
Podemos recuperar un diccionario de la distribución Kali o de SVNDigger por ejemplo. Utilizaremos all.txt de SVNDigger.
Abrimos nuestro editor favorito (nano, vim, etc.) y escribimos el código siguiente:
import urllib2, threading, Queue, urllib
threads = 50
target_url = http://www.ediciones-eni.com"
wordlist_file = /tmp/all.txt
resume = None
user_agent = "Mozilla/5.0 (X11 ; Linux x86_64 ; rv:19.0) Gecko/20100101
Firefox/19.0"
def build_worldlist(worldlist_file) :
fd = open(wordlist_file,"rb")
raw_words...Fuerza bruta autenticación HTML
Cada vez más servidores web cuentan con una protección para los ataques de fuerza bruta como un captcha o una ecuación matemática simple de resolver.
Joomla integra una protección de fuerza bruta bastante clásica y un token de conexión, pero no usa captcha fuertes como protección.
Si queremos probar el sitio remoto, debemos recuperar este token del formulario de login antes de enviar la contraseña y comprobar que se acepta la cookie en urllib2.
Para ello, vamos a utilizar HTMLParser, ya visto en el capítulo de la red.
¿Cómo se gestiona el formulario de login de Joomla?
<form action="/administrator/index.php" method="post" id="form-login"
class='form-inline">
<input name="username" tabindex="1" id="mod-login-username" type="text"
class="input-medium" placeholder="User Name" size="15"/>
<input name="passwd" tabindex="2" id="mod-login-password" type="password"
class="input-medium" placeholder="Password" size="15"/>
<select id="lang" class="inputbox advancedSelect">
<option value="" selected="selected">Langage-Default</option>
<option value="en-GB">English (United Kingdom)</option>
<input type="hidden" name="option" value="com_login"/>
<input...Selenium
1. Introducción
Selenium es una herramienta de automatización del navegador web. Permite escribir, de manera más o menos asistida, scripts cuya ejecución realizará automáticamente acciones en un navegador web: visitar una página, hacer clic en un enlace, rellenar un formulario, etc. y recuperar los resultados de estas acciones.
WebDriver está incluido en Selenium. Vamos a utilizarlo a continuación.
WebDriver se basa en un modelo cliente-servidor. Un cliente de prueba envía "comandos" mediante peticiones HTTP a un servidor WebDriver después de iniciar sesión. Este último distribuye los comandos a los drivers de los navegadores correspondientes. Estos controladores ejecutan los comandos en los navegadores en cuestión empleando mecanismos de automatización internos, del sistema operativo o JavaScript. Es en realidad más complicado que eso, ya que estos controladores pueden por sí mismos ser servidores WebDriver (Internet Explorer), comunicarse a través de web sockets (Safari), etc. El driver no es necesariamente un binario, los drivers de Firefox y Safari son por ejemplo extensiones del navegador.
Por defecto, los navegadores y sus drivers deben estar disponibles en el mismo equipo que el servidor WebDriver (veremos más tarde que podemos hacerlo de otra forma). Pero mediante la arquitectura cliente-servidor, los equipos...
Conexión a un sitio web y navegación
Ahora vamos a insistir en un sitio donde necesitamos autenticarnos. Una vez autenticados, vamos a navegar hasta una página que incluya una gestión del tiempo para recuperarla.
Como ejemplo, nos vamos a conectar al entorno Office 365 de Microsoft.
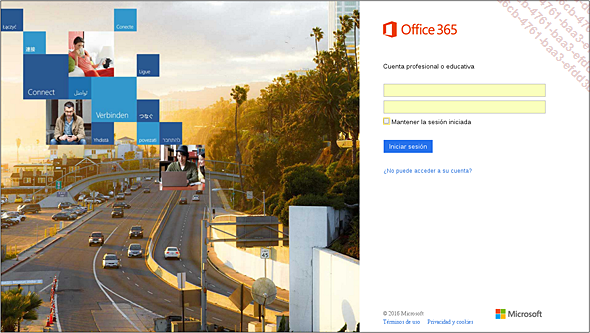
Si probamos a introducir un nombre de usuario y una contraseña y observamos el resultado con una herramienta especializada, veremos que los nombres de los campos son username y password, y para intentar la conexión, submit. Así podemos escribir la parte de conexión de forma bastante simple:
Username = driver.find_element_by_id("username")
username.send_keys("your_login_name")
password = driver.find_element_by_id("password")
password.send_keys("your_password")
driver.find_element_by_name("submit").click()
Para navegar en las páginas, utilizaremos:
move_mouse = driver.find_element_by_link_text("Office 365")
action = ActionChains(driver)
action.move_to_element(move_mouse)
action.perform()
Aquí tendremos que hacer clic en "Office 365" y luego en "Calendario".
Podríamos, una vez llegamos a la página de Calendario, hacer una captura de pantalla. También contamos con un botón "Imprimir", que podremos utilizar para crear un archivo pdf.
También podamos navegar por las distintas semanas con las flechas izquierda y derecha.
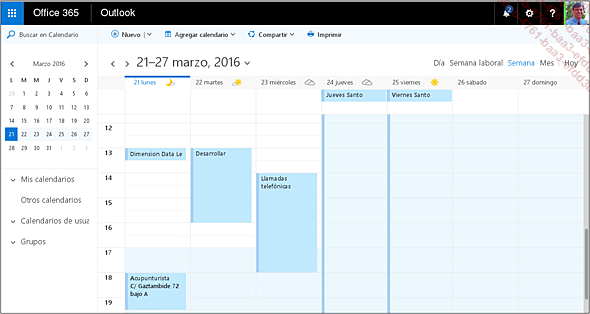
Aquí tenemos un ejemplo de programa completo para esta aplicación específica:
# Función que devuelve el mes en letras
def trad_meses(mes):
mes_traducido = 0
if int(mes) == 1:
mes_traducido = "Enero" ...Conclusión
Existen muchas otras librerías útiles para la Web. Un único libro sobre este tema no sería suficiente. Tratamos aquí de darle las más útiles para probar sitios web y la seguridad. No hemos mostrado la escritura de plug-ins para software especializado, como la suite Burp o Nessus, para esto existen buenos tutoriales disponibles en Internet.
