![Extrait - LINUX Dominar la administración del sistema [6ª edición]](/libro/linux-dominar-la-administracion-del-sistema-6-edicion-9782409046926_m.jpg)
Presentación de Linux
Bienvenidos al mundo Linux
1. Un sistema en evolución
Linux, que tiene más de 30 años, ha pasado de ser un proyecto de estudiante a ser el sistema operativo más utilizado en el mundo. Desde sus primeros desarrollos en 1991 y hasta la fecha de hoy, Linux no ha dejado de evolucionar, cambiar.
Linux ofrece diferentes interfaces gráficas adecuadas para un usuario final. Sin embargo, para la administración de un servidor, es preferible utilizar la interfaz en línea de comandos, gestionada por un programa en modo carácter (shell).
2. El sistema operativo
La función del sistema operativo es administrar el hardware que compone el ordenador y ponerlo a disposición de las aplicaciones. Está compuesto por un núcleo (kernel) y módulos adicionales que varían en función de la configuración de hardware y software de la máquina.
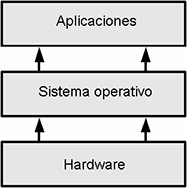
Fundamentos del sistema operativo
El sistema operativo ofrece a los programadores una interfaz de programación de aplicaciones (API, Application Programming Interface): las llamadas de sistema. Por ejemplo, para solicitar la apertura de un archivo, una aplicación utilizará la llamada de sistema open().
El sistema operativo gestiona:
-
la memoria,
-
los periféricos,
-
los datos en los discos,
-
los programas,
-
la seguridad,
-
la recopilación de la información.
A diferencia de otros sistemas operativos (Microsoft Windows en particular), Linux no integra una interfaz gráfica en su sistema operativo propietario. Existen diferentes interfaces, algunas de ellas opcionales y, desde el punto de vista del sistema, son aplicaciones como cualquier otra.
La interfaz gráfica no es un componente del sistema operativo y Linux no la necesita para funcionar. Es un conjunto de programas ejecutados «sobre» el sistema operativo.
Los controladores de la tarjeta gráfica son componentes del sistema operativo: las bibliotecas gráficas se basan en la API propuesta por el controlador para mostrar texto, ventanas o juegos.
Linux es un sistema operativo de tipo Unix (Unix-like). Existen muchos sistemas operativos en esta familia, incluido macOS de Apple. Unix es un sistema operativo multitarea y multiusuario:
-
Multitarea: el sistema gestiona la ejecución simultánea de varios programas llamados procesos.
-
Multiusuario: el sistema permite a varios usuarios trabajar en una misma máquina. Garantiza el control de acceso a los recursos, así como la gestión de programas concurrentes.
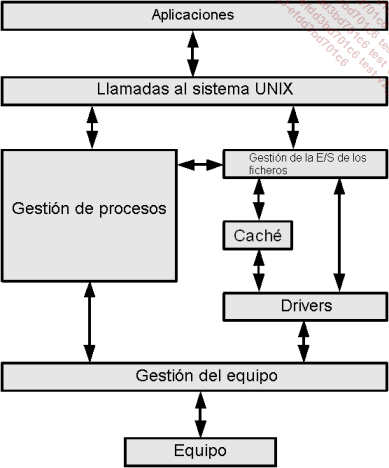
Arquitectura lógica de un sistema de tipo UNIX
El esquema anterior es una síntesis simplificada de la estructura interna de un sistema operativo de tipo Unix:
-
Las llamadas al sistema son utilizadas por los programas para comunicarse...
El software libre
1. Los orígenes del software libre
En 1983, Richard Stallman (RMS), un informático del laboratorio de inteligencia artificial del MIT, decidió escribir un nuevo sistema operativo, de acceso, uso, modificación y redistribución completamente gratuitos. Basado en Unix, lo llamó GNU (Gnu’s Not Unix). Para que este sistema esté operativo, necesita un kernel, un compilador de C y un conjunto de utilidades (para administrar el inicio del sistema, archivos, cuentas de usuario, etc.). Stallman, que ya había escrito el famoso editor de texto Emacs, creó un compilador y luego volvió a desarrollar la mayoría de los comandos de la utilidad Unix.
El diseño de un núcleo es mucho más complejo y requiere una importante fase teórica. Se lanza el proyecto GNU HURD (Hird of Unix Replacing Daemons). Aún no se ha completado, pero la última versión 0.9 data de diciembre de 2016.

Richard Stallman (foto personal del autor)
Para defender el software libre, Richard Stallman creó en 1985 una fundación, la FSF (Free Software Foundation), que difunde las ideas del software libre, en oposición al software “propietario“. Entre sus trabajos, se encuentra la redacción de una licencia especial para el software libre, denominada GPL (General Public License). El software libre garantiza cuatro libertades:
-
Libertad 0: la libertad de utilizar el software.
-
Libertad 1: la libertad de estudiar el funcionamiento del programa y adaptarlo a sus necesidades.
-
Libertad 2: la libertad de redistribuir copias.
-
Libertad 3: la libertad de mejorar el programa y difundir las mejoras al público.
Las libertades 1 y 3 requieren acceso al código fuente del programa. La libertad 3 define la noción de comunidad en torno al software libre.
El software libre (free) se debe entender en el sentido de “libertad“ y no de gratuito. Es completamente legal explotar comercialmente software libre. Pero, según las libertades 2 y 3, debe ser posible obtener una copia editable de forma gratuita.
El desarrollo de HURD avanza lentamente. Sus desarrolladores asumieron el desafío de desarrollar un microkernel: los componentes básicos del sistema operativo están “divididos” en varias subunidades independientes, pero que se deben comunicar entre sí. Esta elección teórica es difícil de implementar técnicamente. Por tanto, el proyecto GNU no tenía un núcleo operativo, es Linux el que permitió hacer realidad el proyecto.
2. GNU/Linux
a. Linus Torvalds
La historia de Linux empieza cuando Linus Torvalds, joven estudiante finés de la universidad de Helsinki de 21 años de edad, adquiere en 1991 un ordenador basado en el procesador...
Las distribuciones
1. ¿Qué es una distribución de Linux?
Una distribución consiste en un kernel Linux, un conjunto de herramientas de software para implementar el sistema y sus servicios, administrar los recursos de la máquina y las cuentas de usuario, y un gran número de aplicaciones. Cada distribución incluye herramientas para instalar el propio sistema operativo y los componentes de software, en forma de paquetes de software (packages). Estos elementos están disponibles a través de Internet, en sitios web llamados "repositorios de software".
Existe un gran número de distribuciones, comerciales o no, orientadas a servidores o estaciones de trabajo o informática integrada. Vamos a presentar los más importantes.
2. Debian

El proyecto Debian fue fundado en 1993 por Ian Murdock, quien falleció en diciembre de 2015. El nombre Debian es una contracción de Debra (su esposa) de su propio nombre de pila, Ian. Debian fue durante mucho tiempo la única distribución compuesta exclusivamente de software libre y código abierto, lo que todavía le ha valido el nombre oficial de Debian GNU/Linux.
Cada versión de Debian lleva el nombre de un personaje de la película Toy Story: Woody, Sid, Jessy, Potato, Buster, etc. Las ventajas de Debian son numerosas:
-
un número de paquetes de software que se cifra en miles,
-
un software de instalación APT, práctico y eficiente,
-
una distribución 100 % de código abierto,
-
una alta estabilidad para un entorno de producción,
-
muchos repositorios de software.
Algunos puntos débiles:
-
paquetes de software que a menudo son antiguos en repositorios estables,
-
actualizaciones de distribución irregulares y muy espaciadas,
-
riesgos asociados a la multiplicación de paquetes y dependencias,
-
instalación y configuración a veces complicadas,
-
un soporte comercial inexistente.
Si una versión estable no es conveniente para usted, puede instalar la versión de desarrollo llamada Sid o habilitar repositorios desde ella. A continuación, tendrá acceso a los componentes más recientes, pero a veces inestables.
Sitio web: https://www.debian.org
A partir de junio de 2023, Debian está en Debian 12 Bookworm estable. La versión con soporte long (LTS, Long Time Support) es Debian 10 ”Buster”, hasta el 30 de junio de 2024.
3. Ubuntu

El creador de la distribución Ubuntu, el multimillonario sudafricano Mark Shuttleworth, es un antiguo informático que contribuyó al proyecto Debian. Creó la distribución Ubuntu Linux en 2005, desarrollada y mantenida por su empresa, llamada Canonical, con un presupuesto inicial de 10 millones de dólares. La palabra Ubuntu es una palabra en la lengua bantú africana que significa "soy lo que soy gracias a lo que somos todos".
Esta distribución, derivada de Debian, tiene como objetivo proporcionar software más reciente potenciando la usabilidad y la ergonomía. Sus puntos fuertes son los siguientes:
-
derivada de Debian,
-
compatible con los paquetes de software de Debian,
-
sistema de instalación muy sencillo,
-
lanza versiones cada 6 meses,
-
entorno gráfico específico y orientado al usuario final.
Esta distribución es ideal como estación de trabajo para usuarios finales, principiantes y estudiantes de informática. Está diseñado para ser fácil de instalar y usar. También se utiliza ampliamente en su versión de servidor para empresas.
Es la distribución más descargada e instalada del mundo. Los diseñadores de Ubuntu son muy innovadores y crean elementos de software específicos regularmente. El número de repositorios y la librería de software son considerables. Hay versiones con soporte a largo plazo (LTS, Long Time Support).
Cada versión va acompañada de un nombre que consta de dos palabras: el nombre de un animal y un adjetivo, en orden alfabético. A menudo, se hace referencia a una versión por su adjetivo: precisa, rara o fiable. Las distribuciones se publican en abril y octubre. El número más alto se corresponde con el año y el más pequeño con el mes (04 o 10)....
¿Qué hardware es compatible con Linux?
1. La arquitectura
Linux es compatible con al menos cuatro arquitecturas físicas actuales:
-
x86 para los ordenadores cuyos procesadores son del tipo Intel (del 386 al Pentium 4) o AMD (Athlon, Duron, Sempron) de 32 bits. Esta versión funciona también en las máquinas con procesadores de 64 bits. De hecho, con la multiplicación de estos últimos, el empleo de Linux en esta arquitectura tiende a desaparecer.
-
x86_64 para los ordenadores cuyos procesadores son del tipo Intel (Pentium 4 a partir de las series 600, Xeon, Dual Core/Quad Core, i3, i5, i7, i9, etc.) o AMD (Athlon 64, Sempron 64, Opteron, Phenom, FX, Ryzen de E1 a E5, etc.) de 64 bits. Esta versión no funciona en los procesadores de 32 bits. Se recomienda utilizar una versión de 64 bits de Linux en los equipos que lo soportan.
-
ARM: esta familia de procesadores se usa fundamentalmente en sistemas embebidos, especialmente en dispositivos multimedia, en ”box” multifunción, en routers, en lectores DVD, DivX y Blu-ray de salón, en GPS o en smartphones y tabletas. Esta arquitectura ha descendido tanto en 32 bits y 64 bits, mono o multiprocesador.
-
PPC para los ordenadores cuyos procesadores son de tipo PowerPC, o sea, los antiguos ordenadores de la marca Apple. Esta versión no se instalará en las últimas máquinas de Apple, basadas en un procesador Intel. Aún existen algunas distribuciones para esta arquitectura. Los PowerPC se siguen utilizando en varias consolas de juegos, como la Wii U o la PS3.
Los ARM y PowerPC son procesadores de tipo RISC. El núcleo Linux soporta completamente RISC. El proyecto RISC-V representa la última generación y algunos constructores están barajando la posibilidad de remplazar las arquitecturas x86 por procesadores de este tipo en los ordenadores de escritorio.
Salvo si el equipo no lo permite, es aconsejable emplear una versión de 64 bits de Linux para permitir al sistema desplegar todo su potencial.
2. Configuración básica del hardware
Linux soporta en teoría todos los tipos...
Obtener información y ayuda sobre Linux
Se ha desarrollado una comunidad muy grande en torno a Linux y el software libre. Los fabricantes de distribuciones proporcionan documentación y soporte. Hay una serie de sitios web con información, guías y foros dedicados a Linux y aplicaciones de código abierto, que incluyen:
Los sitios web de los editores de distribución:
-
Debian: https://www.debian.org/doc/
-
Ubuntu: https://help.ubuntu.com
-
SUSE SLES: https://www.suse.com/documentation/
-
openSUSE: https://en.opensuse.org/Documentation
Los sitios web de comunidades, wikis y foros:
-
Linux: https://linux.org
-
Freecode: https://freshmeat.sourceforge.net
-
Slashdot: https://slashdot.org
-
Foros Fedora: https://forums.fedoraforum.org
-
Foros Debian: https://forums.debian.net/
-
Foros Ubuntu: https://ubuntuforums.org/
-
Foros openSUSE: https://forums.opensuse.org/c/english
Los sitios de documentación:
-
Lea Linux : https://lea-linux.org
-
The Linux Documentation Project : https://tldp.org