
Persistencia
Introducción
No es raro ver en los artículos de prensa la metáfora que compara los datos con combustible. Sin duda, es una metáfora interesante, pero se centra en la necesidad de transformar la energía bruta (como el petróleo) en energía utilizable, como el combustible de los coches. Hay otra característica de los datos que es igual de importante. Está relacionada con la volatilidad de la mayoría de nuestros datos: el almacenamiento. En este sentido, la metáfora de la electricidad es probablemente más apropiada. De hecho, la volatilidad y también las limitaciones (como las que conlleva el Big Data) que impone el almacenamiento de nuestros datos en determinadas condiciones, nos obligan a diseñar soluciones que se puedan adaptar constantemente a cualquier tipo de necesidad.
Por tanto, el almacenamiento (o persistencia) de datos es un componente importante, incluso vital, de la gestión de datos. Sea cual sea el perfil (experto, analista o simple consumidor de información), poder acceder a los datos es esencial. Pero el acceso a los datos también implica conocer el método de almacenamiento subyacente. Este capítulo examina los distintos métodos de almacenamiento y cómo afectan al modo en que se accede a los datos y se utilizan.
Por supuesto, el primer tipo de soporte en el que pensamos es el archivo o, al menos, un conjunto...
Archivos
Del mismo modo que el bit es la unidad primaria para codificar datos, el archivo es en cierto modo la unidad primaria para almacenar un conjunto de datos en un soporte. Las bases de datos, los almacenes de datos (Data Warehouse) y los lagos de datos (Data Lake), funcionan con archivos. Pero cerremos el paréntesis y hablemos de un archivo como unidad de almacenamiento en un soporte.
|
¿Qué es un archivo? Un archivo es un conjunto de datos almacenados y codificados de forma estructurada en un soporte (físico si es un disco duro). Un archivo se identifica por un nombre y, por convención (porque es opcional), puede tener una extensión. |
Los archivos los gestiona y organiza el sistema operativo a través del sistema de archivos, que también puede ser de varios tipos (NTFS, FAT, FAT32, ext2fs, ext3fs, ext4fs, zfs, etc.). En definitiva, no son más que un conjunto de datos vinculados de forma lógica, que se pueden almacenar físicamente en un soporte.
También merece la pena destacar que:
-
Se pueden almacenar varios archivos en uno solo utilizando formatos de almacenamiento como Zip, Tar, etc.
-
Si no almacenan datos como tales, es posible ejecutar archivos (ejecutables) directamente en el sistema operativo.
-
Un archivo está asociado a un tipo de formato (estructura) que identifica su naturaleza. Por ejemplo, sabemos que los archivos de imagen son del tipo jpg, png, etc.
Veamos con más detalle algunos de los tipos de archivo, cuya finalidad es almacenar información.
1. El archivo CSV
Los archivos CSV (Comma Separated Values) son, sin duda, los que encontramos con más frecuencia, porque son muy sencillos y, sobre todo, comprensibles y accesibles por todos los sistemas operativos. También se conocen como archivos planos con separadores por comas. El formato de estos archivos es estructurado porque el formato de los datos (ASCII, UTF-x) es tabular. Por tanto, estos archivos se organizan en filas y columnas y se pueden abrir con un sencillo editor de texto (como Notepad, emacs o vi). También son muy populares porque otras herramientas informáticas como Excel, Calc, etc. pueden abrirlos directamente.
Un punto importante es la forma en que se estructuran los datos en este tipo de archivos. Estos archivos tienen lo que se conoce como delimitadores, para separar columnas y filas. La mayoría de los archivos...
Bases de datos
¿Cómo podríamos escribir un libro sobre datos sin hablar de las bases de datos? Una base de datos sirve para almacenar y organizar un conjunto de datos o información en una única ubicación (no necesariamente física).
Hoy en día existen muchas bases de datos. Por supuesto, cuando hablamos de ellas, pensamos inmediatamente en Oracle, Microsoft SQL Server, IBM DB2, etc. Para simplificar, las primeras que nos vienen a la cabeza son las bases de datos relacionales "históricas" conocidas como SGBD-R (Relational Database Management Systems o Sistema de Gestión de Bases de Datos Relacionales).
En los últimos años, con la creciente cantidad de datos que hay que almacenar (Big Data) y la diversidad de usos, es obligatorio replantearse la forma de gestionar los datos. Han surgido nuevas formas de bases de datos para llenar los vacíos que han dejado las antiguas bases de datos relacionales. Este capítulo examina en particular las bases de datos NoSQL, que ofrecen nuevas formas de almacenar datos no estructurados.
En primer lugar, es importante examinar las principales familias de bases de datos.
1. Familias de bases de datos
Existen varias familias principales de bases de datos:
-
Bases de datos relacionales (SGBD-R). Son las más utilizadas, y volveremos a ellas con más detalle en la siguiente sección.
-
Bases de datos jerárquicas. Como su nombre indica, en este tipo de base de datos la información se almacena en un árbol (por tanto jerárquico), formado por nodos (cada dato) y ramas (enlaces entre dos nodos).
Este tipo de sistema impone una serie de limitaciones:
-
La existencia de un nodo raíz (padre).
-
Un nodo (hijo) solo puede tener un nodo padre.
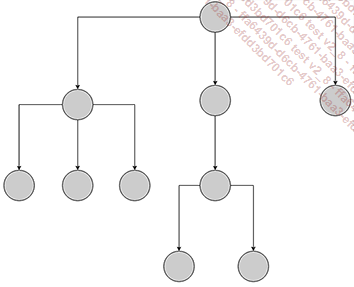
Ilustración de un modelo de datos jerárquico
-
Bases de datos de grafos (o redes): las bases de datos de grafos superan una limitación bastante molesta de las bases de datos jerárquicas, al permitir que un nodo tenga varios hijos además de varios padres.
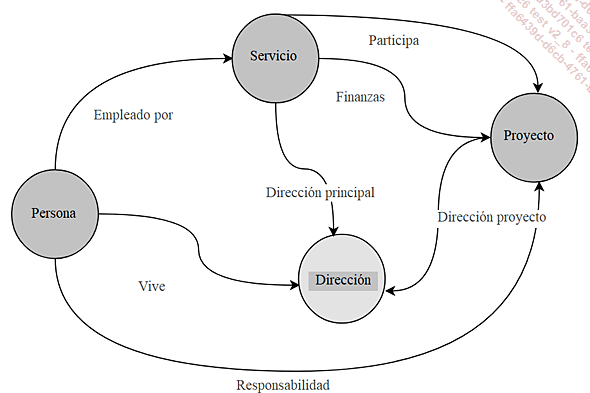
Modelo de datos de tipo grafo
Esto significa que no hay límites en las relaciones entre nodos, por lo que ya no se habla de árbol sino de grafo. El principal uso de este tipo de base de datos es para todo lo relacionado con las recomendaciones.
-
Bases de datos de objetos. Los modelos de bases de datos orientadas a objetos, agrupan conjuntos de datos...
Bases de datos relacionales (SGBD-R)
1. Lenguaje SQL
El lenguaje SQL (Structured Query Language) es el lenguaje normalizado para consultar y actualizar datos en una base de datos relacional. Su primera versión data de 1970 (IBM), y es justo decir que este lenguaje se ha convertido en la referencia para el acceso a los datos. Tanto es así que incluso otros tipos de bases de datos (NoSQL, por ejemplo) se inspiran en él y, sobre todo, tratan de ofrecer un modo de consulta lo más parecido posible a SQL.
Por desgracia, es imposible hablar de SQL sin repasar los principales conceptos de conjunto inherentes a este lenguaje de consulta de datos. SQL se basa en lo que se conoce como consultas. Una consulta es un tipo de instrucción enviada a la base de datos que permite al usuario preguntarle o comunicarse con ella.
Tenga cuidado, porque el lenguaje SQL ha evolucionado y cambiado mucho desde su creación. Algunas veces estos cambios afectan a pequeños detalles y otras incluso difieren en función del SGBR-R. Debe saber que, oficialmente, se han introducido varios estándares (SQL-1, SQL-2, etc.), que también presentan diferencias significativas.
El lenguaje SQL tiene tres tipos principales de sentencias:
-
LMD (Lenguaje de Manipulación de Datos), que se utiliza para consultar datos. Este lenguaje permite actuar directamente sobre los datos almacenados.
-
El LDD o DDL (Lenguaje de Definición de Datos) se utiliza para controlar los datos y crear/modificar/eliminar las estructuras físicas de la base de datos, como índices/tablas, etc.
-
Y LCD (Lenguaje de Control de Datos) para gestionar usuarios/grupos y permisos.
2. LMD / SQL
El objetivo aquí no es examinar en detalle todas las facetas de SQL. No obstante, LMD es realmente un lenguaje fundamental para la consulta de datos. Resulta especialmente interesante porque permite abordar los datos de una forma basada en conjuntos, en lugar de atómica. Por supuesto, este lenguaje se basa en el MPD (Modelo Físico de Datos) y le permitirá consultar los datos de una o varias tablas describiendo los vínculos funcionales.
En este capítulo, echaremos un vistazo rápido a este lenguaje, sin pretender ofrecer un curso sobre SQL, pero sí lo suficiente para ofrecer una guía de referencia rápida sobre los fundamentos de este lenguaje esencial en el mundo de los datos....
Sistemas OLTP y OLAP
Es imposible no mencionar los sistemas OLTP (OnLine Transaction Processing). Este tipo de sistemas de gestión de datos es capaz de manejar aplicaciones orientadas a las transacciones (entrada de pedidos, transacciones financieras, gestión de relaciones con los clientes (CRM) y ventas al por menor).
Hablamos de sistemas operacionales.
Estos sistemas están diseñados para gestionar datos operativos a través de transacciones y suelen tener las siguientes características:
-
Gestión de pequeños conjuntos de datos.
-
Indexación en el acceso a los datos.
-
Un gran número de usuarios/peticiones.
-
Muchas peticiones (CRUD).
-
Una exigencia en términos de tiempo de respuesta.
-
Grandes volúmenes de datos.
Este tipo de sistemas se suele contraponer al tratamiento OLAP (Decisional/OnLine Analytical Processing): este último, por ejemplo, consiste en consultar numerosos registros (a veces incluso todos) de una base de datos, con fines analíticos.
Además, aunque se puede utilizar la misma base de datos para ambos fines, la forma de modelarla debe ser diferente:
-
OLTP -> Modelización relacional
-
OLAP -> Modelización en estrella
Sistema distribuido y teorema CAP
Este teorema CAP se deriva de la observación empíricamente demostrada por Eric Brower de que, en un momento dado, es imposible que un sistema de gestión de datos que funcione como un clúster (funcionamiento distribuido), cumpla las tres restricciones siguientes:
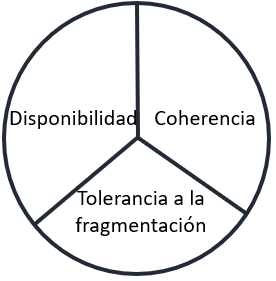
Criterios CAP
-
Coherencia: este criterio certifica que todos los componentes del sistema de gestión de datos contienen exactamente los mismos datos al mismo tiempo.
-
Disponibilidad: se trata de un criterio sencillo que garantiza que todas las peticiones reciban una respuesta.
-
Tolerancia a la fragmentación: en un sistema que funciona con varios nodos (cluster), este criterio exige que los datos, si están fragmentados (repartidos en varios nodos), se deben poder reconstituir en cualquier momento, incluso en caso de fallo de uno de los elementos/nodos.
Los estudios de Eric Bower también demostraron que es posible cumplir un máximo de dos restricciones (en un momento dado), pero nunca las tres. Esto impone ciertos compromisos.
|
CAP son las siglas deConsistency, Availability and Partition tolerance. |
Este teorema repercutirá en los tipos de bases de datos orientadas a clusters, que estudiaremos a continuación. En concreto, este teorema influye en la arquitectura técnica y, en consecuencia, en el sistema de gestión de bases de datos subyacente.
Existen dos tipos principales de arquitectura...
Bases de datos NoSQL
Durante la década de 2010, debido a una sobreabundancia ineludible de datos, y también a la diversidad de estructuras de datos por explotar, en algunos casos las bases de datos alcanzaron muy rápidamente sus límites. De esta desviación surgirá un nuevo paradigma que redistribuirá los criterios CAP al tiempo que aglutinará una serie de iniciativas en torno a los datos. Por tanto, hay que tomar ciertas decisiones y proponer soluciones que respondan a la demanda de disponibilidad, a costa de mantener la coherencia (véase Teorema CAP). En este momento, es cuando las llamadas bases de datos NoSQL (de Not Only SQL o no solo SQL) hacen su aparición.
Estos nuevos sistemas de gestión de datos ponen en entredicho algunos conceptos y principios bien asentados de las bases de datos tradicionales, como las propiedades ACID. Todo ello con un objetivo concreto: gestionar grandes (muy grandes) volúmenes de datos de todo tipo.
Contrariamente a ciertas ideas preconcebidas, esta tendencia NoSQL no se opone a las bases de datos relacionales. Al contrario, completa las lagunas dejadas por estas últimas en los otros dos aspectos del teorema CAP (tolerancia a la fragmentación y disponibilidad), en detrimento, claro está, de la coherencia.
He aquí algunos ejemplos de aplicaciones NoSQL:
-
Apache Cassandra (Columna)
-
MongoDB (Documento)
-
AWS Dynamo, Azure Cosmos DB (Clave-valor)...
El Big Data
Sin duda, la verdadera limitación de las bases de datos tradicionales es la gestión de cantidades de datos muy grandes. Por ejemplo, algunos analistas se apresuran a señalar que cada día se generan alrededor de 2,5 billones de bytes de datos. Es una cantidad enorme y la cifra no deja de aumentar. Durante la década de los años 2000, empresas como Facebook y Google se tuvieron que enfrentar a este problema del Big Data para poder ofrecer más servicios con más datos que gestionar. Por lo tanto, fue necesario pensar en otras formas de gestionar los datos y proponer una alternativa a nuestras famosas bases de datos relacionales (SGBR-R). Pero, sobre todo, era importante establecer prioridades sobre lo que debía ofrecer el nuevo tipo de sistema de almacenamiento.
En la raíz de Big Data están las 3 V.
1. Las 3 V
La noción de Big Data se basa en las 3 V (un concepto introducido por Doug Laney en 2001): volumen, variedad y velocidad. Desde los inicios de Hadoop, esta regla ha sido la ley que deben seguir los llamados sistemas Big Data. Pero, ¿qué significan estas 3 V?
-
V de Volumen. Esto puede parecer obvio cuando hablamos de Big Data pero, desde luego, la primera cualidad de un sistema de Big Data es ser capaz de gestionar una cantidad muy grande de datos. Esta cantidad de datos almacenados puede incluso (con toda probabilidad) seguir creciendo con el paso de los días/horas/segundos. En la actualidad, la cantidad de datos en el mundo se estima en varias decenas de zettabytes o, lo que es lo mismo, varios miles de millones de terabytes. Y, por supuesto, esto es solo el principio.
-
V de Variedad. Esta es una de las características de los sistemas Big Data. Ya no nos limitamos a los datos estructurados. Cada vez es más importante ser capaz de procesar todo tipo de información, estructurada o no. Desgraciadamente, a menudo estos datos son difíciles de utilizar por sí mismos y, dado su enorme volumen, es habitual que no sea posible analizarlos manualmente.
-
V de Velocidad. Al mismo tiempo que debemos ser capaces de gestionar multitud de formatos y tipos de datos, también debemos ser capaces de recibir y actualizar esta información en tiempo real, para poder analizarla con rapidez.
Aunque las 3V están en cierta medida en el origen de las especificaciones de esta nueva...
Tendencias actuales
1. Bases de datos en la nube (Database as a Service: DBaaS)
Hoy en día es posible utilizar bases de datos a través de proveedores externos mediante servicios en la nube. Es lo que se conoce como DBaaS (DataBase as a Service).
Evidentemente, las ventajas de este tipo de uso están estrechamente ligadas a la forma de utilizar la solución:
-
No requiere instalación ni mantenimiento de software/hardware (On-Premise).
-
La gestión de recursos (necesidades de espacio, potencia) es más flexible y adaptable. La ganancia en flexibilidad es significativa porque el servicio lo prestan centros de datos de alto rendimiento.
-
El proveedor automatiza la supervisión, administración y vigilancia de la base de datos.
-
Los expertos del proveedor garantizan la seguridad.
-
Los informes son automáticos y exhaustivos.
Posibles desventajas:
-
Los datos se almacenan fuera de la empresa.
-
En el caso de los datos confidenciales o personales (RGPD), esto puede plantear dudas e incluso problemas en función de la ubicación del centro de datos.
-
En función de los contratos de servicios ofrecidos, los centros de datos pueden no estar disponibles temporalmente (por mantenimiento, etc.).
Hoy en día, existe una gran cantidad de proveedores de DbaaS, entre los que se incluyen varios tipos de actores:
-
Los propios editores de soluciones de bases de datos, que ofrecen sus servicios a través...